왜 멀티 리전 재해 복구가 필요할까?
2019년 8월, AWS 서울 리전에서 대규모 장애가 발생했습니다. 쿠팡, 배달의민족, 업비트 등 서울 리전에만 인프라를 구축했던 서비스들이 수 시간 동안 접속 불가 상태가 되었습니다.
이 사건 이후 많은 기업들이 멀티 리전 아키텍처를 도입하기 시작했습니다. 단일 리전에 모든 것을 배치하면, 그 리전에 장애가 발생했을 때 서비스 전체가 중단됩니다.
재해 복구(Disaster Recovery, DR)란:
- 장애가 발생해도 서비스를 계속 운영할 수 있는 전략과 인프라
- 핵심 질문: "서울 리전이 통째로 다운되면 우리 서비스는 어떻게 되나?"
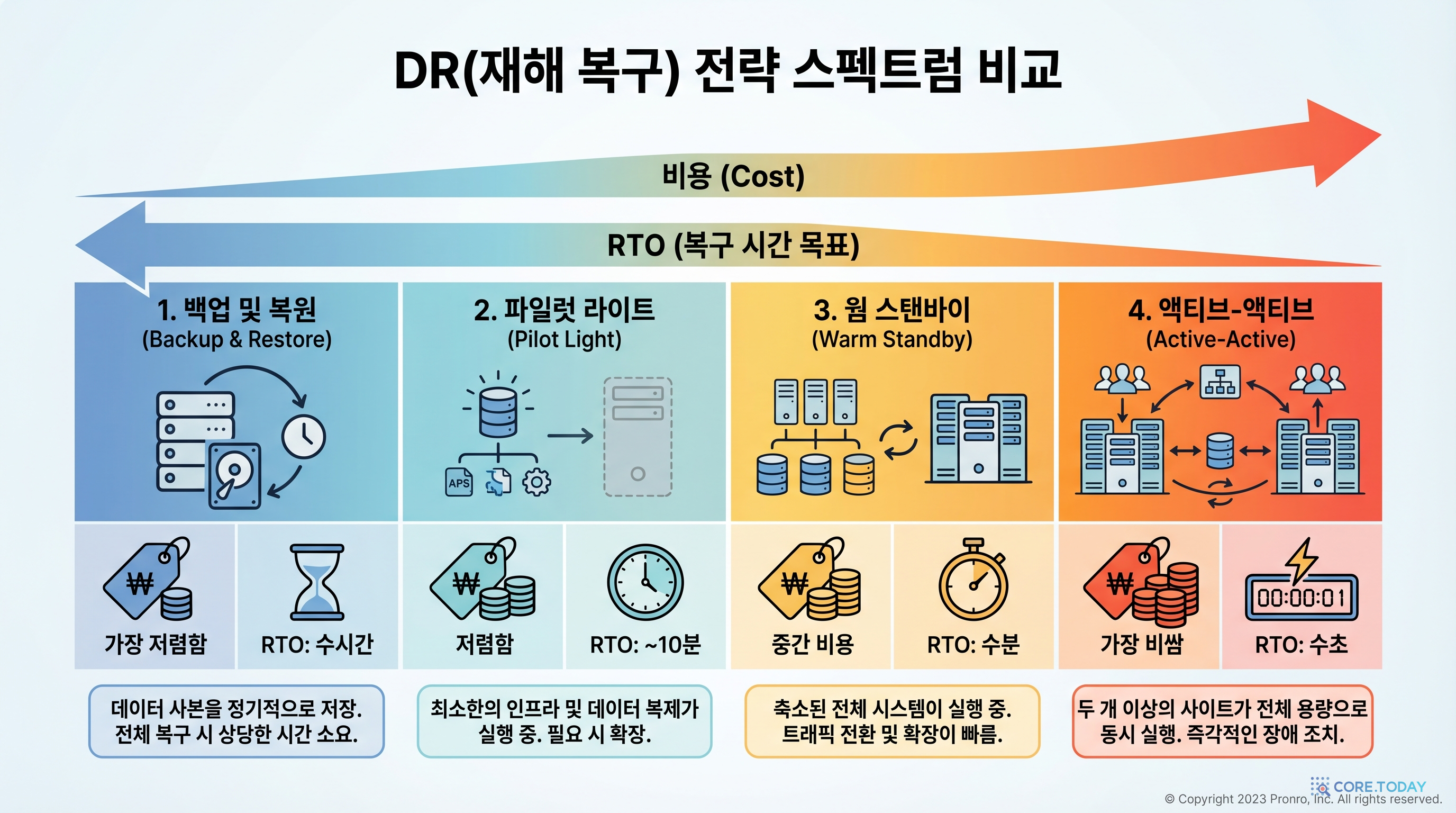
DR 전략에는 4가지 수준이 있습니다 (비용 순):
- Backup & Restore — 백업에서 복원 (가장 저렴, 복구 수 시간)
- Pilot Light — 핵심 DB만 복제 (장애 시 컴퓨팅 구축, 복구 수십 분)
- Warm Standby — 축소 환경 상시 가동 (장애 시 스케일 업, 복구 수 분)
- Active-Active — 양쪽 리전 동시 운영 (즉시 전환, 가장 비쌈)
이 실습에서는 가장 실용적인 Warm Standby 전략을 구현합니다. 서울 리전(Primary)에서 장애 발생 시, 도쿄 리전(Secondary)으로 자동 전환되는 아키텍처를 직접 구축하고 테스트합니다.
이 실습을 마치면 여러분은:
- DR 전략의 4가지 유형과 RPO/RTO 개념을 이해합니다
- Route 53 Failover 라우팅으로 자동 전환을 구현할 수 있습니다
- RDS 크로스 리전 Read Replica를 설정할 수 있습니다
- 실제 장애 시뮬레이션으로 Failover를 테스트할 수 있습니다
이 실습은 고급 수준입니다. VPC 네트워크 설계와 ALB & Auto Scaling 실습을 완료한 후 진행하세요. Primary 리전은 ap-northeast-2 (서울), Secondary 리전은 ap-northeast-1 (도쿄) 을 사용합니다.
비용 주의: 이 실습은 두 리전에 인프라를 배치하므로 비용이 높습니다. RDS, ALB, EC2가 양쪽 리전에서 시간당 비용이 발생합니다. 실습이 끝나면 반드시 양쪽 리전 모두 리소스를 삭제하세요.
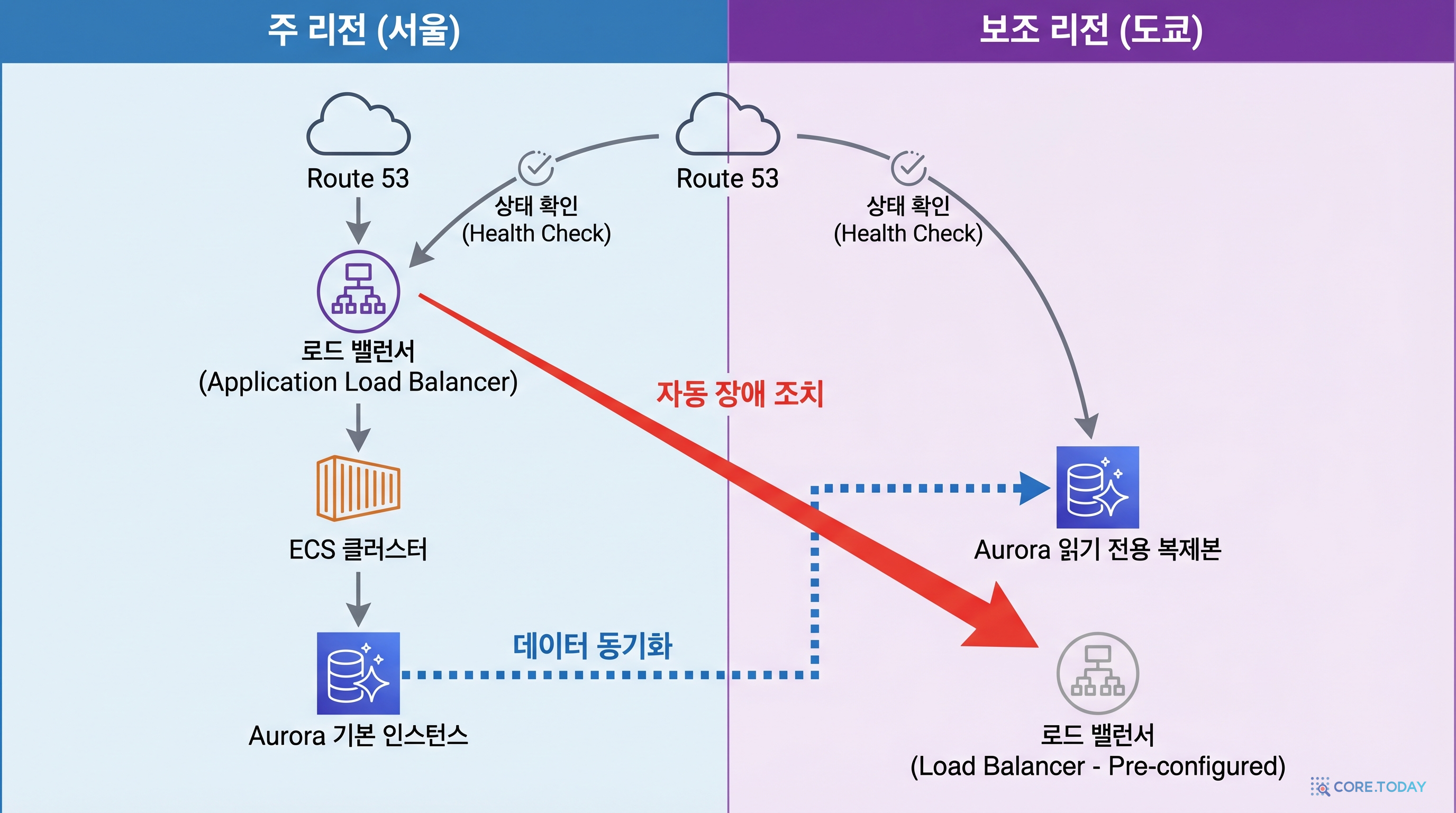
아키텍처 개요
페일오버 흐름
비용 예측
비용 계산기
시간
시간
시간
GB
* 실제 비용은 AWS 요금 정책에 따라 달라질 수 있습니다.
Step 1: DR 전략 이해
본격적인 구축 전에, 4가지 DR 전략의 차이를 명확히 이해합시다. RPO와 RTO라는 두 가지 핵심 지표가 있습니다:
- RPO (Recovery Point Objective): 장애 발생 시 허용 가능한 데이터 손실량
- RPO가 1시간이면: 최대 1시간치 데이터를 잃을 수 있음
- RTO (Recovery Time Objective): 장애 발생부터 서비스 복구까지 허용 가능한 시간
- RTO가 30분이면: 30분 안에 서비스가 다시 정상이어야 함
- 1Backup & Restore (RPO: 시간, RTO: 시간) — 백업에서 복원, 가장 저렴 주기적으로 백업만 다른 리전에 저장. 장애 시 백업으로 전체 인프라 재구축 장점: 비용 최소. 단점: 복구 시간이 길고, 마지막 백업 이후 데이터 손실
- 2Pilot Light (RPO: 분, RTO: 분~시간) — 핵심 DB만 복제, 장애 시 컴퓨팅 확장 DB만 실시간 복제 유지. 장애 시 EC2, ALB 등 컴퓨팅 인프라를 새로 구축 장점: DB 데이터 보존. 단점: 컴퓨팅 구축 시간 필요
- 3Warm Standby (RPO: 초, RTO: 분) — 축소 환경 상시 운영, 장애 시 스케일 업 Secondary에 DB + 최소 컴퓨팅 상시 운영. 장애 시 스케일 업만 하면 됨 장점: 빠른 복구. 단점: 상시 비용 발생
- 4Active-Active (RPO: 0, RTO: 0) — 양쪽 리전 동시 처리, 가장 비쌈 양쪽 리전이 동시에 트래픽 처리. 한쪽 장애 시 즉시 다른 쪽이 전담 장점: 다운타임 없음. 단점: 비용 2배 + 데이터 동기화 복잡
- 5이 실습에서는 Warm Standby 전략을 구현합니다
DR 전략 선택은 비즈니스 요구사항(RPO/RTO)과 비용의 균형입니다. RPO는 허용 가능한 데이터 손실량, RTO는 서비스 복구까지 허용 시간입니다. 대부분의 기업은 비용 대비 효과가 좋은 Warm Standby를 선택합니다.
Step 2: Secondary 리전 인프라 준비 (도쿄)
Warm Standby를 위해 도쿄 리전에도 VPC, 서브넷, ALB, ASG를 구축합니다. 서울 리전과 동일한 구조를 만들되, 축소된 규모로 구성합니다.
- 1리전 전환: AWS 콘솔 우상단에서 리전을 ap-northeast-1 (도쿄)로 변경합니다
- 2VPC 생성 (서울과 동일 구조): VPC: dr-vpc-tokyo, CIDR: 10.1.0.0/16 (서울과 다른 대역 사용) 퍼블릭 서브넷 2개: 10.1.1.0/24 (AZ-a), 10.1.2.0/24 (AZ-c) 프라이빗 서브넷 2개: 10.1.10.0/24 (AZ-a), 10.1.20.0/24 (AZ-c) Internet Gateway, NAT Gateway, 라우팅 테이블 설정
- 3Launch Template 생성: 이름: dr-web-template-tokyo 서울과 동일한 설정 (AMI는 도쿄 리전용으로 변경) User Data 스크립트에 "Region: Tokyo" 표시 추가 (어느 리전인지 확인용)
- 4ALB + Target Group 생성: ALB: dr-alb-tokyo, 퍼블릭 서브넷에 배치 Target Group: dr-tg-tokyo, HTTP:80
- 5Auto Scaling Group 생성 (축소 규모): ASG: dr-asg-tokyo 최소 1, 희망 1, 최대 4 (Warm Standby이므로 최소 인스턴스만 유지) 프라이빗 서브넷에 배치, Target Group 연결
- 6ALB DNS로 접속하여 도쿄 환경이 정상 동작하는지 확인합니다
서울 VPC는 10.0.0.0/16, 도쿄 VPC는 10.1.0.0/16으로 CIDR 대역을 다르게 설정합니다.
나중에 VPC Peering이나 Transit Gateway로 연결할 때 CIDR이 겹치면 안 되기 때문입니다.
Step 3: Route 53 헬스 체크 및 페일오버 설정
Route 53의 Failover 라우팅 정책은 DR의 핵심입니다. 헬스 체크가 Primary를 모니터링하다가, 장애를 감지하면 자동으로 Secondary로 전환합니다.
동작 방식:
- 헬스 체크가 30초마다 Primary ALB에 HTTP 요청을 보냄
- 3회 연속 실패하면 Unhealthy 판정 (약 90초)
- Route 53이 DNS를 Secondary ALB로 전환
- 사용자들이 동일한 도메인으로 접속하면 도쿄로 라우팅됨
- Route 53 콘솔 → 좌측 헬스 체크 → 헬스 체크 생성 클릭
- 헬스 체크 구성:
- 이름:
primary-health-check - 모니터링 대상: 엔드포인트 선택
- 프로토콜: HTTP
- IP 주소 또는 도메인 이름: Primary ALB의 DNS 이름 입력
- 포트: 80
- 경로:
/health(또는/— 웹 서버가 200을 반환하는 경로)
- 이름:
- 고급 구성:
- 요청 간격: 표준 (30초)
- 실패 임계값: 3 (3회 연속 실패 시 Unhealthy)
- 헬스 체크 생성 클릭
- 상태가 Healthy인지 확인합니다 (1~2분 후)
- 이제 호스팅 영역에서 Failover 레코드를 생성합니다:
- 호스팅 영역 선택 (또는 새로 생성) → 레코드 생성
- 라우팅 정책: 장애 조치 선택
- Primary 레코드: A 레코드 → 별칭 → ALB(서울) 선택 → 헬스 체크 연결
- Secondary 레코드: A 레코드 → 별칭 → ALB(도쿄) 선택
- 레코드 생성 클릭
# 헬스 체크 생성
aws route53 create-health-check --caller-reference $(date +%s) \
--health-check-config '{
"FullyQualifiedDomainName":"primary-alb.elb.amazonaws.com",
"Port":80,"Type":"HTTP","ResourcePath":"/health",
"FailureThreshold":3,"RequestInterval":30
}'resource "aws_route53_health_check" "primary" {
fqdn = aws_lb.primary.dns_name
port = 80
type = "HTTP"
resource_path = "/health"
failure_threshold = 3
request_interval = 30
}
resource "aws_route53_record" "primary" {
zone_id = aws_route53_zone.main.zone_id
name = "app.example.com"
type = "A"
set_identifier = "primary"
health_check_id = aws_route53_health_check.primary.id
failover_routing_policy { type = "PRIMARY" }
alias {
name = aws_lb.primary.dns_name
zone_id = aws_lb.primary.zone_id
evaluate_target_health = true
}
}
resource "aws_route53_record" "secondary" {
zone_id = aws_route53_zone.main.zone_id
name = "app.example.com"
type = "A"
set_identifier = "secondary"
failover_routing_policy { type = "SECONDARY" }
alias {
name = aws_lb.secondary.dns_name
zone_id = aws_lb.secondary.zone_id
evaluate_target_health = true
}
}Route 53 호스팅 영역이 없는 경우: 실습용으로 저렴한 도메인을 하나 구입하거나, 기존 도메인이 있다면 사용하세요. Route 53에서 도메인을 구입하면 호스팅 영역이 자동 생성됩니다. 도메인이 없으면 이 단계를 건너뛰고, 각 리전의 ALB DNS로 직접 테스트할 수도 있습니다.
Step 4: RDS 크로스 리전 Read Replica 생성
데이터베이스는 DR에서 가장 중요한 부분입니다. 서버(EC2)는 언제든 새로 만들 수 있지만, 데이터는 한번 잃으면 복구가 불가능합니다.
크로스 리전 Read Replica는 서울의 RDS 데이터를 도쿄로 실시간 복제합니다. 복제는 비동기(Async)로 이루어지며, 보통 수 초 이내의 지연(Replication Lag)이 있습니다.
장애 발생 시 도쿄의 Replica를 독립 인스턴스로 승격(Promote)하면, 읽기/쓰기 모두 가능한 새로운 Primary가 됩니다.
- 서울 리전(ap-northeast-2)에서 시작합니다
- RDS 콘솔 → 데이터베이스에서 Primary DB 인스턴스 선택
- (아직 RDS가 없다면: 데이터베이스 생성 → MySQL, db.t3.micro, 프리티어 템플릿 사용)
- 식별자:
lab-db-primary, 마스터 사용자:admin, 비밀번호 설정 - VPC:
lab-vpc, 프라이빗 서브넷 그룹 사용
- Primary DB 선택 → 작업 → 읽기 전용 복제본 생성 클릭
- 복제본 설정:
- 대상 리전: 아시아 태평양 (도쿄) 선택 (중요!)
- DB 인스턴스 식별자:
lab-db-replica-tokyo - DB 인스턴스 클래스:
db.t3.micro - 스토리지 자동 조정: 비활성화 (실습용)
- 네트워크: 도쿄 VPC의 프라이빗 서브넷 그룹 선택
- 읽기 전용 복제본 생성 클릭
- 생성에 10~15분이 소요됩니다. 상태가 Available이 될 때까지 기다립니다
- 도쿄 리전으로 이동하면
lab-db-replica-tokyo가 보입니다
aws rds create-db-instance-read-replica \
--db-instance-identifier lab-db-replica-tokyo \
--source-db-instance-identifier arn:aws:rds:ap-northeast-2:ACCOUNT:db:lab-db-primary \
--db-instance-class db.t3.micro --region ap-northeast-1resource "aws_db_instance" "replica" {
provider = aws.tokyo
identifier = "lab-db-replica-tokyo"
replicate_source_db = aws_db_instance.primary.arn
instance_class = "db.t3.micro"
skip_final_snapshot = true
}크로스 리전 Read Replica는 비동기 복제를 사용합니다. 장애 시 Replica를 승격(Promote)하여 독립 쓰기 인스턴스로 전환합니다. 승격에는 약 5~10분이 소요됩니다.
Replication Lag 주의: 비동기 복제이므로 수 초의 지연이 있습니다. Failover 시 이 지연 시간만큼의 데이터가 손실될 수 있습니다. 이것이 Warm Standby의 RPO가 "초" 단위인 이유입니다.
Step 5: S3 크로스 리전 복제(CRR)
정적 파일이나 사용자 업로드 파일이 S3에 저장되어 있다면, 이것도 도쿄 리전으로 복제해야 합니다.
S3 크로스 리전 복제(CRR)는 소스 버킷에 새 객체가 업로드되면 자동으로 대상 버킷에 복제하는 기능입니다.
- 1도쿄 리전에서 대상 버킷을 먼저 생성합니다: S3 → 버킷 만들기 → 이름: lab-backup-tokyo-{고유ID}, 리전: ap-northeast-1 버전 관리: 활성화 (CRR의 필수 조건!)
- 2서울 리전으로 돌아옵니다
- 3소스 버킷 선택 → 속성 탭 → 버전 관리 활성화 (CRR은 양쪽 버킷 모두 버전 관리가 활성화되어야 합니다)
- 4소스 버킷 → 관리 탭 → 복제 규칙 생성 클릭
- 5복제 규칙 설정: 규칙 이름: crr-to-tokyo 상태: 활성화 범위: 이 규칙은 버킷의 모든 객체에 적용 선택
- 6대상 설정: 이 계정의 버킷에서 버킷 선택 → lab-backup-tokyo-{고유ID} 선택
- 7IAM 역할: 새 역할 생성 선택 (자동으로 필요한 권한이 부여됨)
- 8저장 클릭
- 9테스트: 소스 버킷에 새 파일 업로드 → 1~2분 후 도쿄 버킷에 복제 확인
주의: CRR은 규칙 생성 이후 업로드된 새 객체만 복제합니다. 기존 객체는 자동 복제되지 않습니다. 기존 객체를 복제하려면 S3 Batch Replication을 사용해야 합니다.
Step 6: 페일오버 테스트
이제 가장 핵심적인 단계 — 실제 장애를 시뮬레이션하고 Failover를 확인합니다. 이 테스트를 통해 DR 아키텍처가 실제로 동작하는지 검증합니다.
장애를 시뮬레이션하는 가장 안전한 방법은 보안 그룹에서 HTTP 트래픽을 차단하는 것입니다. 서울 ALB의 보안 그룹에서 HTTP(80) 규칙을 삭제하면, 헬스 체크가 실패하면서 Failover가 트리거됩니다.
- 1정상 상태 확인: Route 53 도메인(또는 서울 ALB DNS)으로 접속 → 서울 페이지 표시 확인 Route 53 → 헬스 체크 → primary-health-check → Healthy 상태 확인
- 2장애 시뮬레이션 (서울 리전): EC2 콘솔 → 보안 그룹 → 서울 ALB의 보안 그룹 선택 인바운드 규칙 편집 → HTTP(80) 규칙 삭제 → 저장 이것으로 서울 ALB가 외부 트래픽을 받지 못하게 됩니다
- 3Failover 모니터링: Route 53 → 헬스 체크 확인 약 1~2분 후 상태가 Unhealthy로 변경됩니다 DNS 전파에 추가로 30초~1분 소요
- 4Secondary 전환 확인: 동일한 도메인으로 다시 접속 → 도쿄 페이지가 표시되면 Failover 성공! (User Data에 "Region: Tokyo" 표시를 넣었다면 쉽게 구분 가능)
- 5RDS Replica 승격 (필요 시): 도쿄 리전 → RDS 콘솔 → lab-db-replica-tokyo 선택 작업 → 읽기 전용 복제본 승격 클릭 승격 후 이 인스턴스가 독립적인 쓰기 가능 DB가 됩니다 도쿄의 EC2가 이 DB에 연결하도록 설정 변경
- 6복구 테스트: 서울 ALB 보안 그룹에 HTTP(80) 규칙 다시 추가 1~2분 후 헬스 체크가 Healthy로 복구 DNS가 다시 서울로 전환됩니다
- 7각 단계의 시간을 기록합니다 — 이것이 실제 RTO입니다
Failover 테스트는 정기적으로 실행해야 합니다. 실제 장애 상황에서 "Failover가 동작하지 않았다"는 최악의 시나리오를 방지하기 위함입니다. 많은 기업이 분기마다 DR 드릴(Disaster Recovery Drill)을 실시합니다.
핵심 개념 확인
직접 설명해 보기
본인의 말로 설명해 보세요
회사의 CTO에게 Warm Standby DR 전략의 동작 원리를 설명해 보세요. 정상 상태와 장애 상태에서 각각 어떤 일이 일어나는지 포함해 주세요.
💡 정상 시: 서울에서 서비스, 도쿄는 축소 대기. 장애 시: Route 53이 DNS 전환, 도쿄가 스케일 업.
본인의 말로 설명해 보세요
RPO와 RTO의 차이를 비기술적인 비유로 설명해 보세요.
💡 은행 금고에 비유해 보세요. 마지막으로 돈을 넣은 시점과, 금고를 다시 여는 시간.
완성 후 테스트 가이드
전체 DR 아키텍처가 구축되었다면, 다음 체크리스트로 검증하세요.
- 1정상 라우팅 테스트: Route 53 도메인 접속 → 서울 페이지 확인. dig 또는 nslookup으로 DNS가 서울 ALB IP를 반환하는지 확인
- 2헬스 체크 동작 확인: Route 53 → 헬스 체크 → Healthy 상태 확인
- 3Failover 테스트: 서울 ALB 보안 그룹에서 HTTP 삭제 → 1~2분 후 Unhealthy → 도메인 접속 시 도쿄 페이지 확인
- 4Failback 테스트: 서울 보안 그룹 복원 → 1~2분 후 Healthy → 도메인 접속 시 다시 서울 페이지 확인
- 5RDS 복제 확인: 서울 DB에 데이터 INSERT → 도쿄 Replica에서 SELECT로 복제 확인 (수 초 이내)
- 6S3 복제 확인: 서울 버킷에 파일 업로드 → 1~2분 후 도쿄 버킷에 복제 확인
- 7RTO 측정: Failover 전체 과정(장애 발생 ~ 도쿄에서 정상 서비스)의 소요 시간 측정
트러블슈팅
헬스 체크가 계속 Unhealthy인 경우:
- 헬스 체크의 엔드포인트(ALB DNS)가 올바른지 확인
- ALB 보안 그룹에서 Route 53 헬스 체커 IP 범위의 HTTP(80)가 허용되어 있는지 확인
- 헬스 체크 경로(예:
/health)에서 HTTP 200을 반환하는지 직접curl로 테스트 - ALB Target Group의 인스턴스가 healthy인지 확인
Failover 후에도 서울 페이지가 표시되는 경우:
- DNS 캐시 때문일 수 있습니다.
dig app.example.com으로 현재 DNS 레코드 확인 - 브라우저 DNS 캐시 삭제 또는 시크릿 모드로 테스트
- TTL 값이 높으면 DNS 전파에 시간이 걸림 — Route 53 레코드의 TTL을 60초로 설정
- Route 53 Failover 레코드가 올바르게 구성되었는지 확인 (Primary/Secondary 설정)
RDS Replica 생성이 실패하는 경우:
- 원본 DB에 자동 백업이 활성화되어 있는지 확인 (Replica 생성의 전제 조건)
- 도쿄 리전에 DB 서브넷 그룹이 있는지 확인
- IAM 권한이 충분한지 확인 (RDS 크로스 리전 복제 권한 필요)
- 원본 DB가 암호화되어 있다면, 대상 리전에 KMS 키가 있어야 합니다
S3 CRR이 동작하지 않는 경우:
- 양쪽 버킷 모두 버전 관리가 활성화되어 있는지 확인 (필수 조건!)
- 복제 규칙 생성 이전 객체는 복제되지 않음 → 새 객체 업로드로 테스트
- IAM 역할에 소스 버킷 읽기 + 대상 버킷 쓰기 권한이 있는지 확인
확장 아이디어
- Active-Active 구성: 양쪽 리전에 동일 규모 인프라를 배치하고, Route 53 지연 시간 기반 라우팅으로 가까운 리전에서 서비스하기.
- Aurora Global Database: RDS 대신 Aurora를 사용하면 크로스 리전 복제가 더 빠르고 안정적입니다. 1초 미만의 RPO를 달성할 수 있습니다.
- 자동화된 Failover Runbook: AWS Systems Manager Automation으로 Failover 절차(RDS 승격, ASG 스케일 업 등)를 자동화해 보세요.
- DR 모니터링 대시보드: CloudWatch Dashboard에 양쪽 리전의 상태, 복제 지연, 비용 등을 한눈에 볼 수 있는 대시보드를 만들어 보세요.
- Chaos Engineering: AWS Fault Injection Simulator로 더 정교한 장애 시뮬레이션(AZ 장애, 네트워크 지연 등)을 해 보세요.
학습 정리
핵심 치트시트
이 프로젝트에서는 Warm Standby DR 전략을 구현하여, Primary(서울) 장애 시 Secondary(도쿄)로 자동 전환되는 멀티 리전 아키텍처를 구축했습니다. Route 53 Failover, RDS 크로스 리전 복제, S3 CRR이 핵심 구성 요소입니다.
리소스 정리
실습 완료 후 양쪽 리전 모두 아래 순서대로 리소스를 정리하세요. 특히 RDS와 ALB는 시간당 비용이 높으므로 반드시 삭제합니다.
- Route 53 페일오버 레코드 및 헬스 체크 삭제
- RDS Read Replica 삭제 (도쿄) — 최종 스냅샷 생략 체크
- RDS Primary 삭제 (서울) — 최종 스냅샷 생략 체크
- S3 복제 규칙 삭제 → 양쪽 버킷 비우기(비우기 클릭) 및 삭제
- Auto Scaling Group 삭제 (양쪽 리전 — 인스턴스 자동 종료)
- ALB, Target Group 삭제 (양쪽 리전)
- NAT Gateway 삭제 + Elastic IP 릴리스 (양쪽 리전)
- 시작 템플릿, 보안 그룹 삭제 (양쪽 리전)
- 서브넷, IGW 분리/삭제, 라우팅 테이블 삭제 (양쪽 리전)
- VPC 삭제 (양쪽 리전)