왜 이걸 만들까? — 수천 건의 데이터를 AI가 자동 처리해야 할 때
여러분이 이커머스 회사의 데이터 엔지니어라고 상상해 보세요.
매일 고객 리뷰가 500건씩 올라옵니다. 마케팅팀은 "리뷰의 감성(긍정/부정)을 분석해 주세요"라고 요청하지만, 500건을 사람이 일일이 읽고 분류하는 건 불가능합니다.
AI 챗봇(이전 실습)에서는 1건씩 실시간으로 처리했습니다. 하지만 이번에는 다릅니다:
- 500건을 한꺼번에 자동으로 처리해야 합니다
- 처리 중 일부가 실패하더라도 나머지는 계속 진행해야 합니다
- 모든 결과를 S3에 저장하고, 완료 시 알림을 보내야 합니다
- 매일 같은 시간에 자동으로 실행되면 좋겠습니다
이런 요구사항은 단순 Lambda 하나로는 해결할 수 없습니다. AWS Step Functions이 필요한 순간입니다.
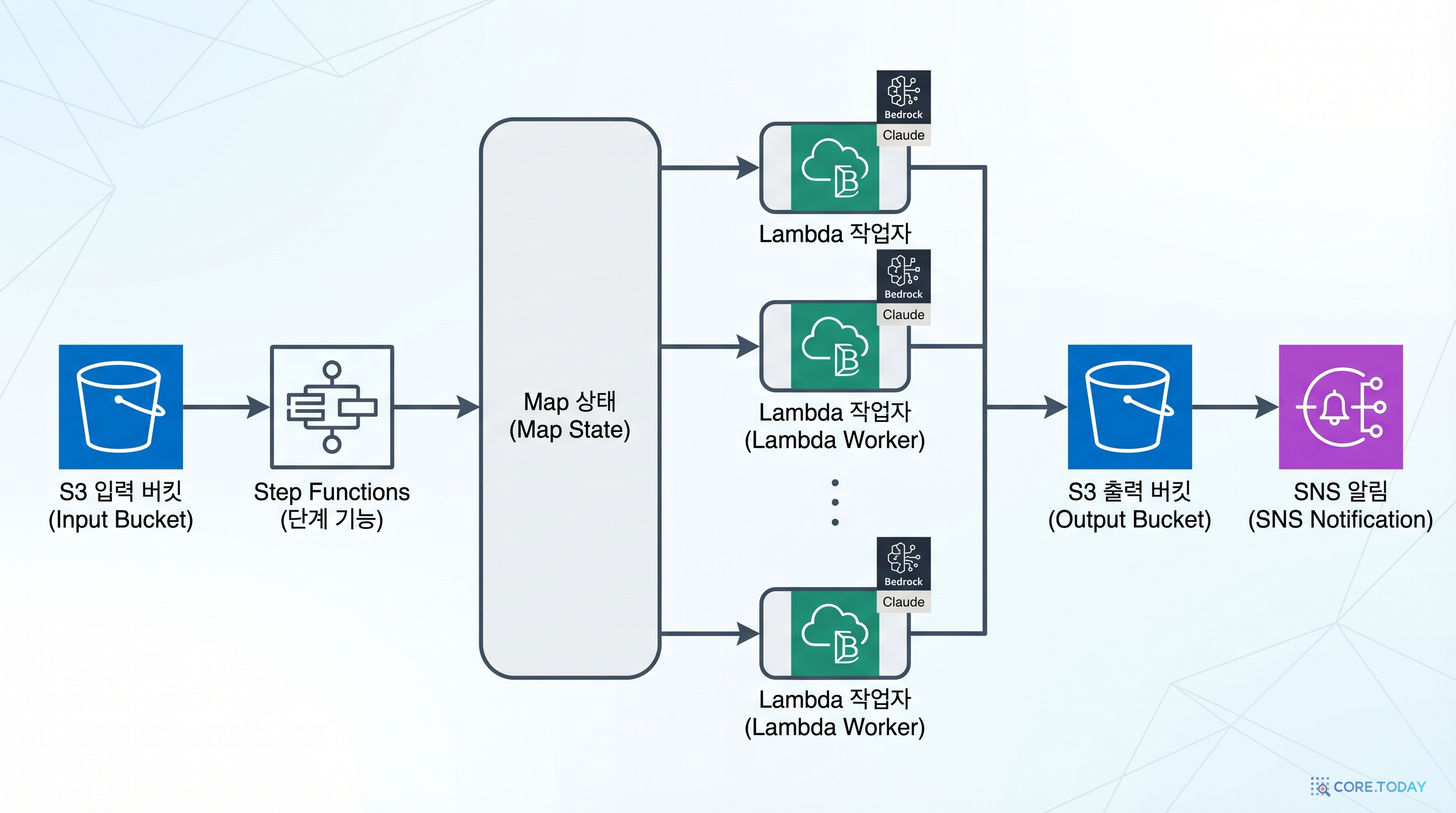
Step Functions는 여러 Lambda 함수를 워크플로(Workflow)로 연결하는 오케스트레이션 서비스입니다. 특히 Map 상태를 사용하면, 입력 배열의 각 항목을 병렬로 처리할 수 있습니다.
이 실습에서는:
- S3: 입력 데이터(리뷰 목록)와 추론 결과를 저장
- Lambda: 각 리뷰를 Bedrock Claude에 보내 감성 분석 수행
- Step Functions: Map 상태로 리뷰 배열을 병렬 처리, 에러 처리/재시도 내장
- SNS: 파이프라인 완료 시 이메일 알림 발송
완성하면 JSON 파일 하나를 Step Functions에 넣으면, 각 항목이 자동으로 AI 분석되고 결과가 S3에 저장되며, 완료 알림 이메일이 도착합니다.
이 프로젝트를 통해 배우게 되는 것:
- Step Functions 워크플로 설계: Map 상태를 사용한 병렬 배치 처리
- 에러 복원력: Retry/Catch로 개별 실패가 전체 파이프라인을 중단시키지 않는 설계
- Bedrock 배치 추론: API 쿼터를 고려한 동시 실행 수 제어
- 이벤트 기반 알림: SNS를 활용한 파이프라인 완료 알림
- 추론 vs 학습: Lambda가 ML에서 어떤 역할을 하는지 이해
실습을 시작하기 전에 AWS 콘솔에 로그인되어 있는지 확인하세요. 리전은 us-east-1 (버지니아 북부) 을 사용합니다. Bedrock 모델 접근 권한이 사전에 활성화되어 있어야 합니다.
아키텍처 개요
파이프라인 실행 흐름
비용 예측
비용 계산기
1K 토큰
1K 토큰
요청
전환
* 실제 비용은 AWS 요금 정책에 따라 달라질 수 있습니다.
Step 1: Bedrock 모델 접근 활성화
이전 실습(AI 챗봇 with Bedrock)에서 이미 활성화했다면 이 단계를 건너뛰어도 됩니다. 하지만 반드시 us-east-1 리전에서 Claude 3 Haiku 모델 상태가 "접근 허용됨"인지 확인하세요.
- Bedrock 콘솔 → 모델 접근 → 모델 접근 관리
- Anthropic Claude 3 Haiku 모델의 상태 확인 → "접근 허용됨"이 아닌 경우 활성화 요청
- 사용 사례 설명 입력 후 승인 대기 (보통 즉시 승인)
- Playground에서 "이 리뷰의 감성을 분석해 주세요: 배송이 빨라서 만족합니다" 테스트
- 정상적으로 감성 분석 결과가 반환되면 준비 완료
aws bedrock list-foundation-models \
--query "modelSummaries[?modelId=='anthropic.claude-3-haiku-20240307-v1:0'].{id:modelId,status:modelLifecycle.status}" \
--output tableBedrock 모델은 리전별로 접근 권한을 별도 활성화해야 합니다. Claude 3 Haiku는 비용이 가장 저렴하면서도 배치 처리에 적합한 성능을 제공합니다. 입력 토큰당 $0.00025, 출력 토큰당 $0.00125 수준입니다.
Step 2: Lambda 추론 함수 생성
이 Lambda 함수는 단일 리뷰 텍스트를 받아 Bedrock Claude에게 감성 분석을 요청하고, 결과를 S3에 JSON으로 저장합니다. Step Functions의 Map 상태가 이 함수를 배열의 각 항목마다 호출합니다. 따라서 이 함수는 1건만 처리하는 단순한 구조로 설계합니다.
- 1Lambda 콘솔 → 함수 생성 → 새로 작성
- 2함수 이름: bedrock-inference-fn
- 3런타임: Python 3.12 선택
- 4아키텍처: arm64 (비용 절감)
- 5실행 역할: 새 역할 생성 → 이름: lambda-bedrock-inference-role
- 6역할에 정책 추가: AmazonBedrockFullAccess + AmazonS3FullAccess (실습용; 프로덕션에서는 최소 권한)
- 7일반 구성: 메모리 256 MB, 타임아웃 60초 설정
- 8코드 작성 핵심 흐름: event에서 item_id, input_text, output_bucket 파싱 bedrock-runtime 클라이언트로 Claude 3 Haiku invoke_model() 호출 프롬프트: "다음 고객 리뷰의 감성을 분석하세요. 긍정/부정/중립으로 분류하고, 핵심 키워드 3개를 추출하세요." Bedrock 응답을 파싱하여 S3 results/{item_id}.json에 저장
- 9Deploy 클릭 → 테스트 이벤트로 단건 처리 정상 동작 확인
Lambda 실행 역할 권한 누락 주의: 이 함수는 Bedrock API 호출과 S3 쓰기를 모두 수행합니다. 실행 역할에 두 서비스 모두에 대한 권한이 있어야 합니다. 권한이 누락되면 AccessDeniedException이 발생하며, CloudWatch 로그에서 어떤 서비스에 대한 권한이 부족한지 확인할 수 있습니다.
중간 점검: Lambda 단건 테스트
Step Functions 워크플로를 구성하기 전에, Lambda 함수가 단독으로 정상 작동하는지 반드시 확인합니다. 복잡한 파이프라인에서 문제가 생기면 원인 추적이 어렵기 때문에, 가장 작은 단위부터 검증하는 것이 핵심입니다.
테스트 이벤트 JSON:
{
"item_id": "test_001",
"input_text": "배송이 빨라서 매우 만족합니다.",
"output_bucket": "ml-pipeline-lab-계정ID"
}Lambda 콘솔에서 테스트 버튼을 클릭하고, S3 results/test_001.json 파일이 생성되었는지, 내용에 감성 분석 결과가 포함되어 있는지 확인합니다. 이 단계에서 문제가 없어야 다음으로 진행합니다.
Step 3: Step Functions 워크플로 구성
Step Functions는 이 파이프라인의 지휘자(Conductor) 역할을 합니다. 입력 배열을 받아 각 항목을 Lambda로 분배(Map 상태)하고, 모든 처리가 끝나면 결과를 집계하여 SNS로 알림을 보냅니다. 개별 항목이 실패해도 나머지는 계속 처리됩니다(Retry/Catch 설정).
- Step Functions 콘솔 → 상태 머신 생성 → 유형: 표준 선택
- 이름:
ml-inference-pipeline - Workflow Studio (시각적 편집기) 사용 권장 — 드래그 앤 드롭으로 워크플로 구성
- 워크플로 구성:
- Map 상태 추가: ItemsPath =
$.items, MaxConcurrency = 5 (동시 5건 처리) - Map 내부에 Lambda Invoke 추가 →
bedrock-inference-fn선택 - Map 상태에 Retry 설정: MaxAttempts=2, BackoffRate=2, IntervalSeconds=5
- Map 상태에 Catch 설정: 에러 시 에러 내용을 결과에 포함
- Map 완료 후 SNS Publish 추가 → 토픽 ARN 입력 (Step 5에서 생성)
- Map 상태 추가: ItemsPath =
- IAM 역할: Lambda 호출 및 SNS 발행 권한을 포함하는 역할 자동 생성
- 상태 머신 생성 클릭
aws stepfunctions create-state-machine \
--name ml-inference-pipeline \
--definition file://pipeline-definition.json \
--role-arn arn:aws:iam::ACCOUNT_ID:role/StepFunctionsMLPipelineRole본인의 말로 설명해 보세요
기획자에게 'Step Functions의 Map 상태가 하는 일'을 택배 물류센터 비유로 설명해 보세요.
Step 4: S3 입출력 및 파이프라인 실행
실제 데이터를 준비하고 파이프라인을 실행합니다. 고객 리뷰 3~5건을 JSON 형식으로 작성하여 입력으로 사용합니다. Step Functions 콘솔에서 실행 상태를 실시간으로 모니터링할 수 있습니다.
- 1S3 버킷 생성: ml-pipeline-lab-{계정ID} (리전: us-east-1)
- 2input/ 폴더와 results/ 폴더 생성
- 3입력 JSON 파일을 로컬에서 작성 — 예시: { "items": [ {"item_id": "review_001", "input_text": "배송이 빨라서 매우 만족합니다. 포장도 깔끔해요.", "output_bucket": "ml-pipeline-lab-계정ID"}, {"item_id": "review_002", "input_text": "상품이 설명과 달라 실망했습니다. 반품 처리도 느려요.", "output_bucket": "ml-pipeline-lab-계정ID"}, {"item_id": "review_003", "input_text": "가격 대비 괜찮은 품질이에요. 보통입니다.", "output_bucket": "ml-pipeline-lab-계정ID"} ] }
- 4Step Functions 콘솔 → ml-inference-pipeline → 실행 시작 → 위 JSON 붙여넣기
- 5그래프 뷰에서 각 Map 항목의 실행 상태 실시간 확인 (녹색 = 성공, 빨간색 = 실패)
- 6모든 항목 완료 후 S3 results/ 폴더에서 각 항목별 추론 결과 JSON 확인
- 7결과 JSON에 감성(긍정/부정/중립), 핵심 키워드, 신뢰도 등이 포함되었는지 확인
Step 5: 결과 집계 및 SNS 완료 알림
파이프라인이 완료되면 팀에게 자동으로 이메일 알림을 보내도록 SNS를 설정합니다. 이메일에는 처리 건수, 성공/실패 건수, S3 결과 경로가 포함됩니다.
- 1SNS 콘솔 → 주제 생성 → 유형: 표준 → 이름: ml-pipeline-complete
- 2구독 생성 → 프로토콜: 이메일 → 본인 이메일 주소 입력
- 3수신된 확인 이메일에서 Confirm subscription 링크 클릭 (이 단계를 빠뜨리면 알림이 안 감!)
- 4Step Functions 상태 머신에서 SNS Publish 단계의 토픽 ARN을 방금 생성한 ml-pipeline-complete ARN으로 업데이트
- 5파이프라인을 다시 실행
- 6모든 항목 처리 완료 후 이메일로 완료 알림 수신 확인
- 7S3 results/ 폴더의 모든 결과 파일을 다운로드하여 감성 분석 결과 집계 확인
Map 상태의 MaxConcurrency를 조정하여 동시 실행 수를 제어할 수 있습니다.
Bedrock API 쿼터를 초과하지 않도록 적절한 값으로 설정하세요.
프로덕션 환경에서는 에러 처리를 위해 Retry와 Catch 블록을 추가합니다.
SNS 이메일 구독 확인을 잊지 마세요: 구독 생성 후 이메일로 확인 링크가 발송됩니다. 이 링크를 클릭하지 않으면 구독 상태가 "확인 대기 중"으로 남아 알림이 전송되지 않습니다. 스팸 메일함도 확인하세요.
핵심 개념 확인
트러블슈팅 가이드
Step Functions 실행에서 Map 항목이 실패할 때:
- Step Functions 콘솔 → 실행 세부 정보 → 실패한 항목의 Input/Output 탭에서 에러 메시지 확인
- Lambda CloudWatch 로그(
/aws/lambda/bedrock-inference-fn)에서 상세 에러 추적 - Bedrock API 쿼터 초과: MaxConcurrency 값을 낮추세요 (예: 5 → 2)
- 개별 항목
input_text가 비어 있거나 형식이 잘못된 경우 Lambda에서 에러 발생
Bedrock ThrottlingException 에러:
- Bedrock API에는 리전별/모델별 요청 쿼터가 있습니다 (기본 초당 5~10건)
- Step Functions Map의
MaxConcurrency를 쿼터 이하로 설정 - Lambda 코드에 exponential backoff 재시도 로직 추가 (3초 → 6초 → 12초)
- AWS Support에 쿼터 증가 요청도 가능
Step Functions IAM 역할 권한 부족:
- 상태 머신의 IAM 역할에 Lambda Invoke 권한(
lambda:InvokeFunction)이 있는지 확인 - SNS Publish 권한(
sns:Publish)이 해당 토픽 ARN에 대해 허용되어 있는지 확인 - Workflow Studio에서 자동 생성된 역할은 보통 올바르지만, 수동 생성 시 누락될 수 있음
완성 후 테스트 가이드
전체 파이프라인을 체계적으로 검증하세요:
- 단건 테스트: Lambda 함수를 직접 테스트 이벤트로 호출 → S3에 결과 JSON 생성 확인
- 파이프라인 실행: 3건 입력 → Step Functions 그래프 뷰에서 모든 항목 녹색(성공) 확인
- 결과 검증: S3
results/폴더에 3개의 JSON 파일 존재 확인 → 감성, 키워드, 신뢰도 포함 여부 - 에러 핸들링: 의도적으로 빈
input_text항목 추가 → Retry 후 Catch에서 처리되는지 확인 - SNS 알림: 파이프라인 완료 후 이메일 수신 확인
- 성능 측정: 5건 처리 시간 vs 10건 처리 시간 비교 → MaxConcurrency 효과 확인
- 비용 확인: Bedrock 콘솔에서 토큰 사용량 확인, Step Functions 콘솔에서 상태 전환 수 확인
- 재실행 테스트: 동일 입력으로 파이프라인을 다시 실행 → S3 결과가 덮어쓰기/중복 없이 처리되는지 확인
확장 아이디어
- EventBridge 자동 트리거: S3에 새 파일 업로드 시 자동으로 Step Functions가 시작되도록 EventBridge 규칙 설정
- 멀티 모델 비교: 동일 리뷰를 Claude Haiku, Claude Sonnet, Titan으로 각각 처리하여 결과 품질/비용 비교
- 결과 대시보드: DynamoDB에 분석 결과를 저장하고, API Gateway + Lambda로 대시보드 조회 API 구축
- 스케줄 실행: EventBridge Scheduler로 매일 오전 9시에 자동 실행되는 일일 배치 파이프라인 구성
- Bedrock Batch Inference: Bedrock의 네이티브 배치 추론 API를 활용하면 Lambda 없이도 대량 처리가 가능 — 비용 50% 절감
Step Functions ASL(Amazon States Language) 핵심 구조
Step Functions의 워크플로를 정의하는 JSON 구조를 이해하면 커스터마이징이 훨씬 수월합니다:
{
"Comment": "ML Inference Pipeline",
"StartAt": "ProcessItems",
"States": {
"ProcessItems": {
"Type": "Map",
"ItemsPath": "$.items",
"MaxConcurrency": 5,
"Iterator": {
"StartAt": "InvokeInference",
"States": {
"InvokeInference": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:ACCOUNT:function:bedrock-inference-fn",
"Retry": [
{
"ErrorEquals": ["States.TaskFailed"],
"IntervalSeconds": 5,
"MaxAttempts": 2,
"BackoffRate": 2.0
}
],
"End": true
}
}
},
"Next": "SendNotification"
},
"SendNotification": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:us-east-1:ACCOUNT:ml-pipeline-complete",
"Message": "ML 추론 파이프라인이 완료되었습니다."
},
"End": true
}
}
}Retry 설정 설명:
IntervalSeconds: 5— 첫 번째 재시도는 5초 후BackoffRate: 2.0— 두 번째 재시도는 10초 후 (5 x 2)MaxAttempts: 2— 최대 2번 재시도 (총 3번 시도) 이 설정으로 Bedrock API 일시적 스로틀링을 자동으로 극복할 수 있습니다.
실습 후 사고 실험
실습에서는 3건의 리뷰를 처리했습니다. 실제 운영 환경에서는 어떻게 확장할까요?
일 500건 처리 시나리오:
- MaxConcurrency=10으로 설정하면, 50배치 x 각 30초 ≈ 약 25분 소요
- Bedrock 비용: 500건 x 평균 500토큰 = 250K 입력토큰 ≈ 약 $0.06/일
- Step Functions 비용: 500 상태전환 x $0.000025 = $0.0125/일
에러 복원력 시나리오:
- 500건 중 3건이 Bedrock 타임아웃 → Retry로 자동 재시도 후 2건 성공, 1건 최종 실패
- Catch 블록이 실패 항목을 별도 에러 리스트에 기록 → 나중에 재처리 가능
- 나머지 497건은 정상 처리 — 전체 파이프라인은 성공으로 완료
학습 정리
핵심 치트시트
Amazon Bedrock + Lambda + Step Functions으로 배치 ML 추론 파이프라인을 구축했습니다. Step Functions Map 상태가 입력 배열의 각 항목을 병렬로 Lambda에 분배하고, 각 Lambda가 Bedrock Claude를 호출하여 감성 분석을 수행합니다. 결과는 S3에 저장되고, 완료 시 SNS로 이메일 알림이 발송됩니다.
핵심 개념
- •Step Functions 상태 머신 — AWS의 서버리스 워크플로 오케스트레이션 서비스. 여러 Lambda, AWS 서비스 호출을 시각적으로 연결하고, 분기/병렬/에러 처리를 선언적으로 정의합니다. JSON 기반 ASL(Amazon States Language)로 워크플로를 기술합니다.
- •Map 상태 — 입력 배열의 각 항목에 대해 동일한 워크플로를 반복 실행하는 Step Functions 상태. MaxConcurrency로 동시 실행 수를 제어하여 하류 서비스(Bedrock API)의 쿼터를 초과하지 않도록 합니다.
- •Retry / Catch — Step Functions의 에러 처리 메커니즘. Retry는 일시적 오류(타임아웃, 스로틀링) 시 자동 재시도하고, Catch는 재시도 소진 후 대체 경로(에러 로깅 등)로 분기합니다. 개별 항목 실패가 전체 파이프라인을 중단시키지 않습니다.
- •추론(Inference) vs 학습(Training) — 추론은 학습된 모델에 데이터를 입력하여 예측 결과를 받는 것(Lambda에 적합). 학습은 대량의 데이터로 모델 가중치를 조정하는 것(SageMaker에 적합). 이 파이프라인은 추론만 수행합니다.
- •Bedrock API 쿼터 — 리전/모델별로 초당 최대 요청 수가 제한됩니다. 쿼터를 초과하면 ThrottlingException이 발생합니다. MaxConcurrency 조절과 exponential backoff로 대응합니다.
- •SNS (Simple Notification Service) — 게시-구독(Pub/Sub) 메시징 서비스. 토픽에 메시지를 발행하면 구독자(이메일, SQS, Lambda 등)에게 전달됩니다. 파이프라인 완료 알림, 에러 알림 등에 활용됩니다.
흔한 실수
- Step Functions Map의 MaxConcurrency를 너무 높게 설정하여 Bedrock API 쿼터 초과(ThrottlingException)
- Lambda 실행 역할에 Bedrock 또는 S3 권한 누락으로 AccessDeniedException
- SNS 이메일 구독 확인 링크를 클릭하지 않아 알림 미수신
- Step Functions IAM 역할에 Lambda 호출 권한 누락
- 입력 JSON의 items 배열 형식 오류로 Map 상태 시작 실패
- Lambda 타임아웃(3초 기본값)을 변경하지 않아 Bedrock 응답 전에 함수 종료
| Lambda 직접 호출 (단건 처리) | Step Functions 파이프라인 (배치 처리) |
|---|---|
| 1건을 즉시 처리 | N건을 병렬로 자동 처리 |
| 에러 시 호출자가 재시도 구현 | Retry/Catch로 자동 재시도 |
| 모니터링: CloudWatch 로그만 | 시각적 실행 그래프로 실시간 추적 |
| 완료 알림 직접 구현 필요 | SNS 연동으로 자동 알림 |
| 단순한 1회성 호출에 적합 | 정기 배치/복잡한 워크플로에 적합 |
본인의 말로 설명해 보세요
비기술 직군의 팀장에게 'Step Functions 파이프라인이 없이 Lambda만으로 500건을 처리하면 어떤 문제가 생기는지'를 설명해 보세요.
리소스 정리
실습 완료 후 반드시 아래 순서대로 리소스를 정리하여 불필요한 과금을 방지하세요.
- Step Functions 상태 머신 삭제 (
ml-inference-pipeline) - Lambda 함수 삭제 (
bedrock-inference-fn) - SNS 주제 및 구독 삭제 (
ml-pipeline-complete) - S3 버킷 비우기 및 삭제 (
ml-pipeline-lab-{계정ID}) - IAM 역할 삭제 (Lambda용, Step Functions용)
- CloudWatch 로그 그룹 삭제 (Lambda, Step Functions)