시나리오: 24시간 멈추면 안 되는 점검 포털
여러분은 대한설비(주)의 클라우드 엔지니어로 첫 출근했습니다. 공장장이 긴급 회의를 소집합니다:
"우리 공장에는 3교대 근무자가 24시간 설비를 점검합니다. 점검 기록을 적는 포털이 한 번이라도 다운되면, 그 시간 동안의 점검 기록이 사라집니다. 절대 죽지 않는 포털을 만들어 주세요."
서버 한 대로 운영하면 어떻게 될까요? 그 서버가 장애를 일으키는 순간, 모든 현장 근무자가 점검 기록을 남길 수 없게 됩니다.
해결책은 고가용성(High Availability) 아키텍처입니다.
- VPC: 포털 전용 네트워크 공간
- ALB(Application Load Balancer): 트래픽을 여러 서버에 분배
- EC2 인스턴스 2대 이상: 하나가 죽어도 다른 서버가 대신 처리
- Auto Scaling Group: 트래픽 증가 시 자동으로 서버 추가
이 실습을 마치면 여러분은:
- 실제 EC2 인스턴스를 강제 종료해도 서비스가 계속되는 것을 확인합니다
- 부하 테스트를 통해 Auto Scaling이 서버를 자동으로 늘리는 것을 직접 목격합니다
- 이후 미니 프로젝트에서 이 인프라 위에 API와 서비스를 올릴 것입니다
이 프로젝트는 스마트 설비 운영 지원 플랫폼 시리즈의 첫 번째입니다. 총 4개 프로젝트를 순서대로 진행하며, 이 인프라 위에 API(2편), 서버리스 서비스(3편), 통합 플랫폼(4편)을 올려 하나의 완성된 시스템을 만듭니다.
실습을 시작하기 전에 AWS 콘솔에 로그인되어 있는지 확인하세요. 리전은 ap-northeast-2 (서울) 을 사용합니다.
아키텍처 개요
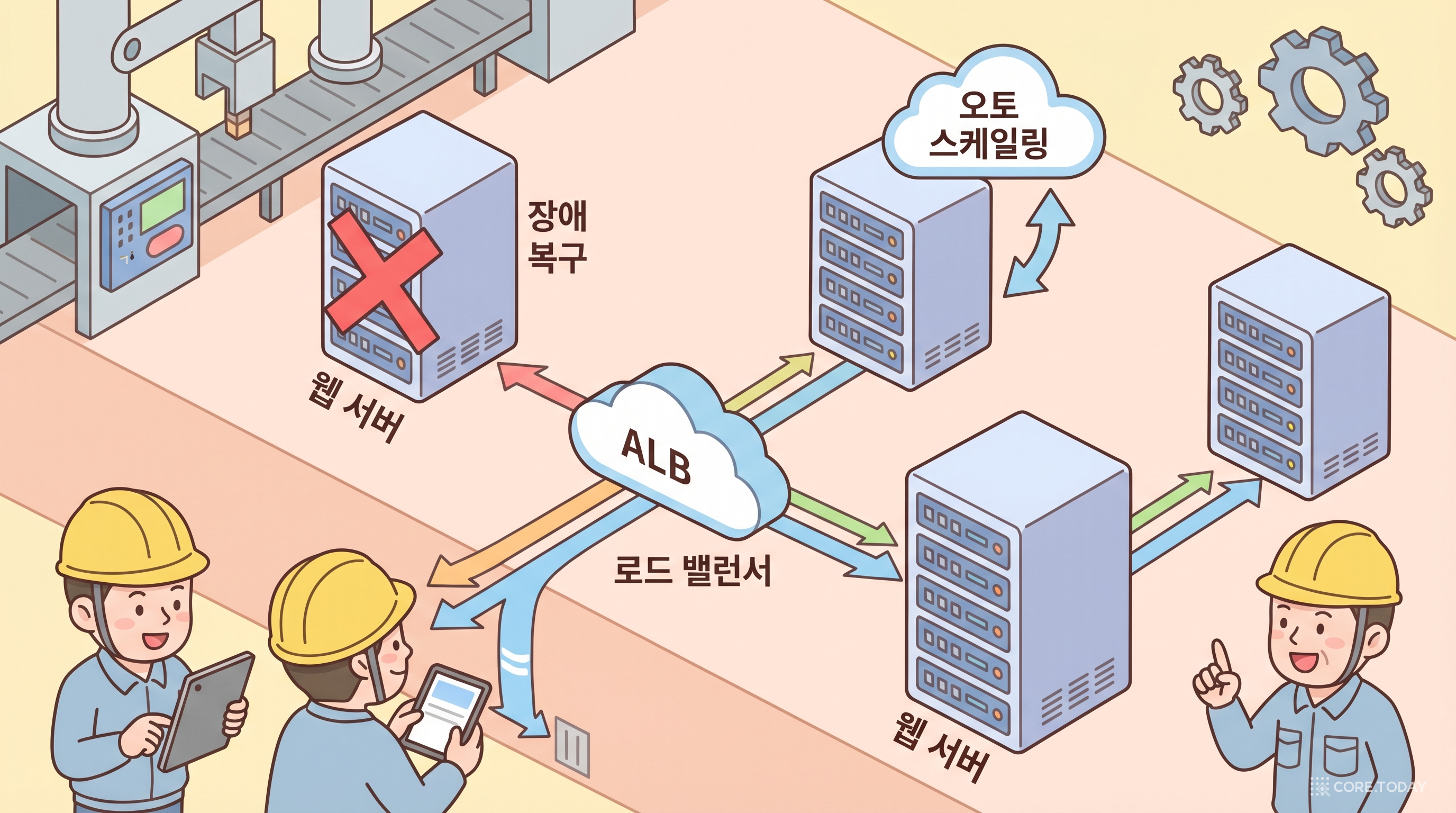
트래픽 흐름
비용 예측
비용 계산기
시간
시간
GB
* 실제 비용은 AWS 요금 정책에 따라 달라질 수 있습니다.
Step 1: VPC 및 네트워크 구성
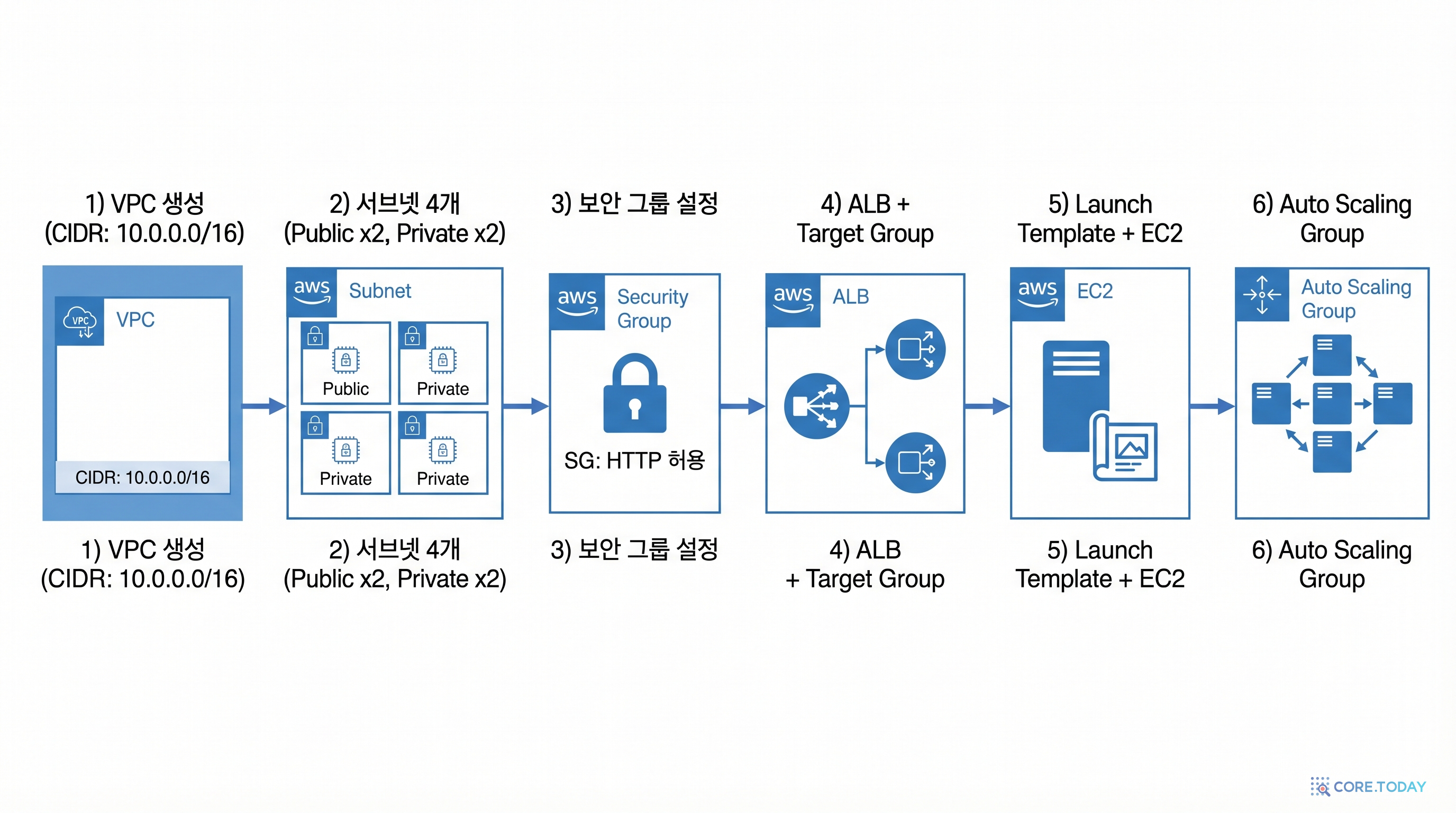
포털 전용 VPC를 만들고, 2개 가용 영역에 퍼블릭 서브넷을 배치합니다. ALB와 EC2 모두 퍼블릭 서브넷에 배치하여 외부 접근이 가능하도록 합니다.
- 1AWS 콘솔 → VPC 검색 → VPC 생성 클릭
- 2VPC 등 옵션을 선택합니다 (이번에는 자동 생성을 활용합니다)
- 3이름 태그 접두사: inspection 입력
- 4IPv4 CIDR 블록: 10.1.0.0/16 입력
- 5가용 영역(AZ) 수: 2 선택
- 6퍼블릭 서브넷 수: 2, 프라이빗 서브넷 수: 0 (이 실습에서는 퍼블릭만 사용)
- 7NAT 게이트웨이: 없음 선택 (비용 절약)
- 8VPC 생성 클릭 → 생성 완료까지 약 1분 대기
- 9생성된 VPC ID를 메모합니다 (vpc-xxxxxxxx)
이전 VPC 미니 프로젝트에서는 각 구성 요소를 하나씩 만들었습니다. 이번에는 "VPC 등" 옵션으로 한 번에 생성하여 시간을 절약합니다. 실무에서는 상황에 따라 두 가지 방법을 적절히 사용합니다.
Step 2: 보안 그룹 생성
ALB용과 EC2용 보안 그룹을 각각 만듭니다. 핵심은 EC2가 ALB에서 오는 트래픽만 허용하도록 설정하는 것입니다.
- 1VPC 콘솔 → 보안 그룹 → 보안 그룹 생성
- 2ALB 보안 그룹 생성: 이름: inspection-alb-sg VPC: inspection-vpc 선택 인바운드: HTTP(80) — 소스 0.0.0.0/0 (모든 곳에서 접근) 아웃바운드: 모든 트래픽 허용 (기본값) 생성 클릭
- 3EC2 보안 그룹 생성: 이름: inspection-ec2-sg VPC: inspection-vpc 선택 인바운드: HTTP(80) — 소스 inspection-alb-sg (ALB 보안 그룹 선택!) 인바운드: SSH(22) — 소스 내 IP (디버깅용) 아웃바운드: 모든 트래픽 허용 (기본값) 생성 클릭
중요: EC2 보안 그룹의 HTTP 인바운드 소스에 0.0.0.0/0이 아닌 ALB 보안 그룹 ID를 넣어야 합니다.
이렇게 하면 ALB를 거치지 않고 EC2에 직접 접근하는 것을 차단하여 보안이 강화됩니다.
Step 3: EC2 시작 템플릿 (Launch Template) 생성
Auto Scaling Group이 새 인스턴스를 만들 때 사용하는 설계도입니다. User Data 스크립트로 EC2가 시작되자마자 자동으로 웹 서버를 실행하도록 설정합니다.
- 1EC2 콘솔 → 좌측 시작 템플릿 → 시작 템플릿 생성
- 2시작 템플릿 이름: inspection-portal-template
- 3AMI: Amazon Linux 2023 선택
- 4인스턴스 유형: t3.micro (프리 티어 대상)
- 5키 페어: 기존 키 페어 선택 (없으면 새로 생성)
- 6네트워크 설정: 보안 그룹: inspection-ec2-sg 선택
- 7고급 세부 정보 → 사용자 데이터에 아래 스크립트 입력:
#!/bin/bash
yum update -y
yum install -y httpd stress-ng
INSTANCE_ID=$(ec2-metadata -i | cut -d' ' -f2)
AZ=$(ec2-metadata -z | cut -d' ' -f2)
cat <<'HTMLEOF' > /var/www/html/index.html
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="UTF-8">
<title>설비 점검 포털</title>
<style>
body { font-family: sans-serif; max-width: 600px; margin: 60px auto; text-align: center; }
.status { padding: 20px; border-radius: 12px; background: #e8f5e9; margin: 20px 0; }
h1 { color: #1565c0; }
</style>
</head>
<body>
<h1>설비 점검 포털</h1>
<div class="status">
<p><strong>서버 상태:</strong> 정상 운영 중</p>
<p><strong>인스턴스 ID:</strong> INSTANCE_PLACEHOLDER</p>
<p><strong>가용 영역:</strong> AZ_PLACEHOLDER</p>
</div>
<p>이 페이지가 보이면 서버가 정상 동작 중입니다.</p>
</body>
</html>
HTMLEOF
sed -i "s/INSTANCE_PLACEHOLDER/$INSTANCE_ID/" /var/www/html/index.html
sed -i "s/AZ_PLACEHOLDER/$AZ/" /var/www/html/index.html
systemctl start httpd
systemctl enable httpd이 스크립트는 EC2 인스턴스가 시작될 때 자동으로 실행됩니다:
yum install httpd stress-ng— Apache 웹 서버와 부하 테스트 도구를 설치합니다- 인스턴스 메타데이터 조회 — 자신의 인스턴스 ID와 가용 영역을 확인합니다
- HTML 페이지 생성 — 어떤 인스턴스가 응답하는지 확인할 수 있는 점검 포털 페이지를 만듭니다
- httpd 시작 — 웹 서버를 시작하고 부팅 시 자동 실행되도록 등록합니다
stress-ng는 나중에 CPU 부하 테스트에 사용합니다.
HTML에 인스턴스 ID와 가용 영역을 표시하면, ALB가 어떤 서버로 트래픽을 보내는지 새로고침할 때마다 확인할 수 있습니다. 이것이 바로 로드 밸런싱의 동작 원리를 눈으로 확인하는 방법입니다.
Step 4: ALB (Application Load Balancer) 생성
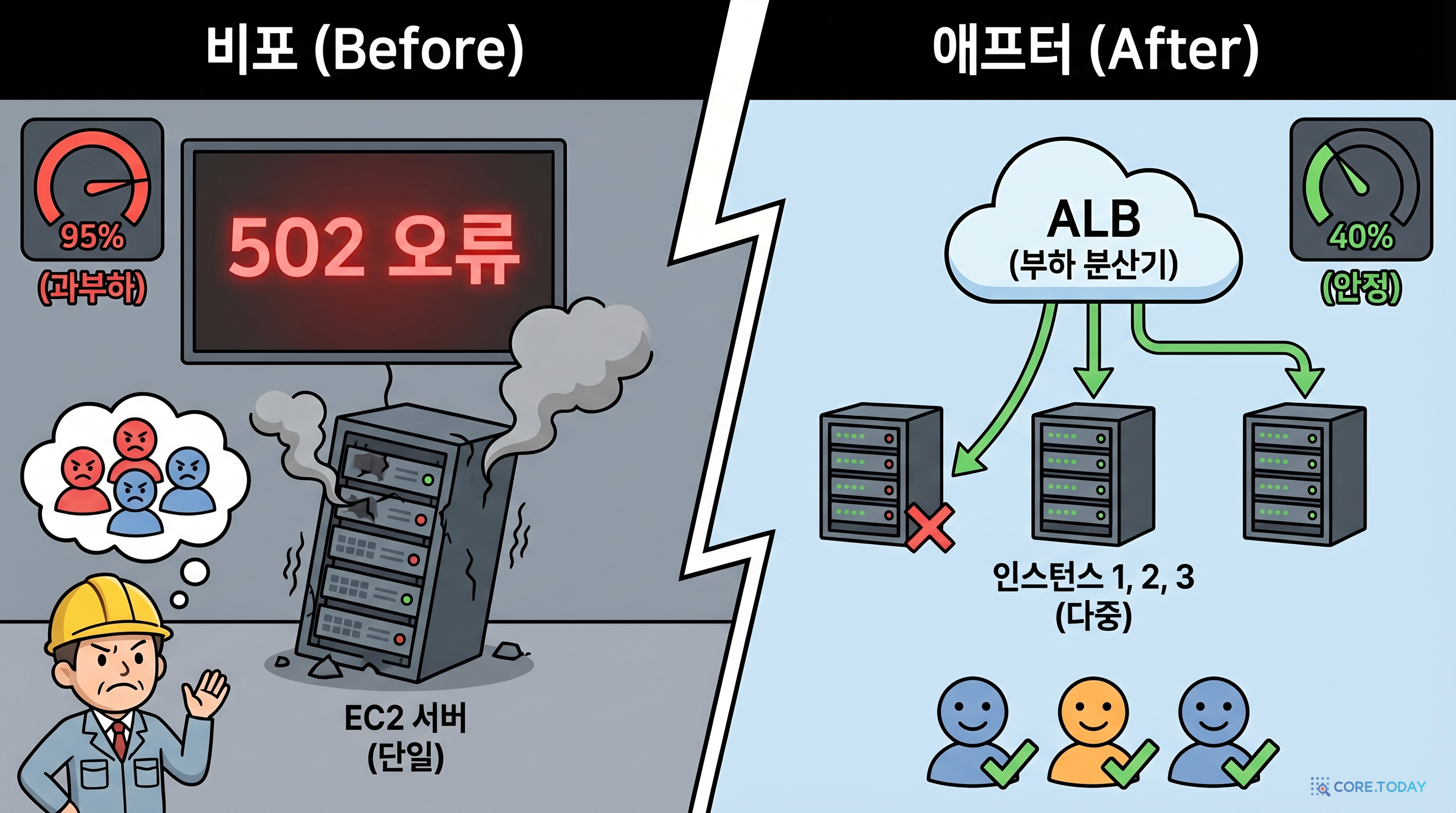
ALB는 들어오는 요청을 건강한 EC2 인스턴스에만 분배하는 교통 경찰입니다. Health Check로 인스턴스 상태를 주기적으로 확인하고, 비정상 인스턴스에는 트래픽을 보내지 않습니다.
- 1EC2 콘솔 → 좌측 로드 밸런서 → 로드 밸런서 생성
- 2Application Load Balancer 선택 → 생성
- 3기본 구성: 이름: inspection-alb 체계: 인터넷 경계 IP 주소 유형: IPv4
- 4네트워크 매핑: VPC: inspection-vpc 선택 가용 영역: ap-northeast-2a, ap-northeast-2c 모두 체크 (퍼블릭 서브넷 선택)
- 5보안 그룹: inspection-alb-sg 선택 (기본 보안 그룹은 제거)
- 6리스너 및 라우팅: 프로토콜: HTTP, 포트: 80 대상 그룹 생성 링크 클릭 → 새 탭이 열립니다
- 7대상 그룹 생성 (새 탭에서): 대상 유형: 인스턴스 이름: inspection-tg 프로토콜/포트: HTTP / 80 VPC: inspection-vpc Health Check 경로: / 고급 Health Check 설정: 정상 임계값 2, 비정상 임계값 3, 시간 초과 5초, 간격 10초 다음 → 대상 등록은 건너뛰기 (ASG에서 자동 등록) → 대상 그룹 생성
- 8로드 밸런서 생성 탭으로 돌아가서 → 새로고침 아이콘 클릭 → inspection-tg 선택
- 9로드 밸런서 생성 클릭
- 10ALB의 DNS 이름을 메모합니다 (inspection-alb-xxxxxxxxx.ap-northeast-2.elb.amazonaws.com)
Health Check 설정이 매우 중요합니다! 간격(10초)과 비정상 임계값(3)에 따라, 인스턴스 장애 감지까지 최대 30초가 걸립니다. 프로덕션에서는 이 값을 서비스 특성에 맞게 조정해야 합니다.
Step 5: Auto Scaling Group 생성
ASG는 항상 최소 2대의 EC2를 유지하고, 트래픽이 증가하면 자동으로 서버를 추가합니다. 인스턴스가 비정상이면 자동으로 교체합니다.
- 1EC2 콘솔 → 좌측 Auto Scaling 그룹 → Auto Scaling 그룹 생성
- 2이름: inspection-asg
- 3시작 템플릿: inspection-portal-template 선택 → 다음
- 4네트워크: VPC: inspection-vpc 가용 영역 및 서브넷: 퍼블릭 서브넷 2개 모두 선택 → 다음
- 5로드 밸런싱: 기존 로드 밸런서에 연결 선택 기존 로드 밸런서 대상 그룹에서 선택 → inspection-tg 선택 Health Check 유형: ELB 체크 (ALB의 Health Check 결과도 반영) → 다음
- 6그룹 크기: 원하는 용량: 2 최소 용량: 2 최대 용량: 4
- 7크기 조정 정책: 대상 추적 크기 조정 정책 선택 지표 유형: 평균 CPU 사용률 대상 값: 60 (CPU 60% 초과 시 Scale Out) → 다음 → 다음 → Auto Scaling 그룹 생성
- 8인스턴스 탭에서 2개의 EC2가 InService 상태가 되기까지 약 2~3분 대기
Step 6: 동작 확인 — ALB 접속 테스트
- 1EC2 콘솔 → 로드 밸런서 → inspection-alb 선택 → DNS 이름 복사
- 2브라우저에서 http://<ALB-DNS-이름> 접속
- 3"설비 점검 포털" 페이지가 나타나는지 확인합니다
- 4인스턴스 ID와 가용 영역을 확인합니다
- 5브라우저를 새로고침합니다 → 인스턴스 ID가 바뀌는지 확인합니다
- 6여러 번 새로고침하면 두 인스턴스에 번갈아가며 요청이 분배되는 것을 볼 수 있습니다
새로고침할 때마다 인스턴스 ID가 바뀌면 ALB의 로드 밸런싱이 정상 동작하는 것입니다. 브라우저 캐시 때문에 같은 인스턴스에 계속 연결될 수 있으니, 시크릿 모드나 curl 명령어를 사용하세요.
장애 복구 데모: EC2 인스턴스 강제 종료
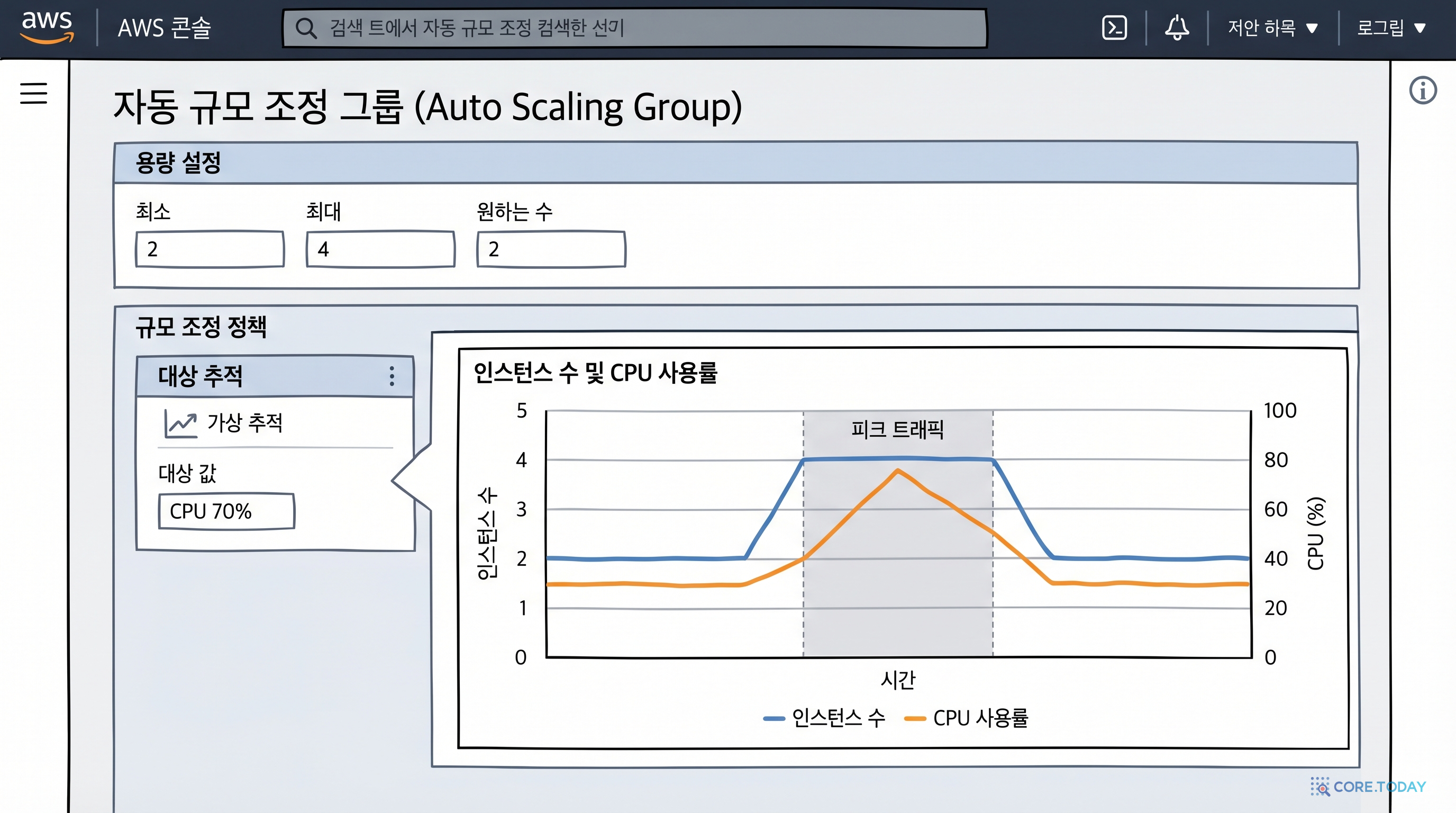
이제 이 아키텍처의 핵심을 확인합니다. EC2 하나를 죽여도 서비스가 계속되는가?
- 1EC2 콘솔 → 인스턴스 → ASG가 만든 인스턴스 2대가 보입니다
- 2인스턴스 하나를 선택 → 인스턴스 상태 → 인스턴스 종료 클릭
- 3"정말 종료하시겠습니까?" → 종료 확인
- 4브라우저에서 ALB DNS로 계속 접속합니다 → 서비스가 중단되지 않습니다!
- 5살아있는 인스턴스의 ID만 표시되는 것을 확인합니다
- 6약 1~2분 후 ASG가 자동으로 새 인스턴스를 생성합니다
- 7EC2 콘솔에서 새 인스턴스가 running 상태가 된 것을 확인합니다
- 8다시 새로고침하면 두 개의 서로 다른 인스턴스 ID가 번갈아 나타납니다
이것이 고가용성입니다. 서버 한 대가 죽어도 사용자는 전혀 눈치채지 못합니다. ALB의 Health Check가 비정상 인스턴스를 감지하면 해당 인스턴스로 트래픽을 보내지 않고, ASG는 인스턴스 수를 원하는 용량(2대)으로 자동 복구합니다.
부하 테스트: Auto Scaling 트리거
CPU 사용률을 인위적으로 높여서 Auto Scaling이 새 인스턴스를 추가하는 것을 확인합니다.
SSH로 EC2에 접속한 후 stress-ng로 CPU 부하를 발생시킵니다:
# EC2에 SSH 접속
ssh -i key.pem ec2-user@<EC2-퍼블릭-IP>
# CPU 코어 2개를 100%로 5분간 사용
stress-ng --cpu 2 --timeout 300s
# 별도 터미널에서 CPU 사용률 모니터링
top외부에서 ab (Apache Bench)로 대량 요청을 보낼 수도 있습니다:
# macOS/Linux에서 실행
# 동시 접속 50개, 총 10,000회 요청
ab -n 10000 -c 50 http://<ALB-DNS-이름>/
# 또는 hey 도구 사용 (brew install hey)
hey -n 10000 -c 50 http://<ALB-DNS-이름>/- 1위 방법 중 하나로 부하를 발생시킵니다
- 2CloudWatch 콘솔 → 지표 → EC2 → Auto Scaling 그룹별 → CPU 사용률 확인
- 3CPU가 60%를 넘으면 약 3~5분 후 ASG가 Scale Out을 시작합니다
- 4EC2 콘솔에서 인스턴스가 2대에서 3대 또는 4대로 증가한 것을 확인합니다
- 5ALB에 접속하면 새로 추가된 인스턴스의 ID도 나타납니다
- 6부하를 중단하면 약 5~10분 후 Scale In으로 다시 2대로 줄어듭니다
직접 설명해 보기
본인의 말로 설명해 보세요
공장장에게 'ALB + Auto Scaling'이 어떻게 포털을 24시간 운영 가능하게 하는지 비전문가도 이해할 수 있게 설명해 보세요.
💡 은행 창구에 비유해 보세요. 대기 고객이 늘면 창구를 열고, 줄어들면 닫는 것과 같습니다.
본인의 말로 설명해 보세요
ALB의 Health Check가 '비정상'으로 판단하면 어떤 일이 순서대로 일어나는지 설명해 보세요.
💡 Health Check 간격, 비정상 임계값, 대상 그룹, ASG의 역할을 포함하세요.
완성 후 테스트 가이드
- 1ALB 접속 테스트: 브라우저에서 ALB DNS 주소로 접속하여 포털 페이지가 표시되는지 확인
- 2로드 밸런싱 확인: 시크릿 모드에서 여러 번 새로고침하여 인스턴스 ID가 바뀌는지 확인
- 3장애 복구 테스트: EC2 인스턴스 1대를 종료 → 서비스 중단 없이 접속되는지 확인 → 새 인스턴스 자동 생성 확인
- 4Auto Scaling 테스트: stress-ng 또는 ab로 부하 발생 → CloudWatch에서 CPU 확인 → 인스턴스 수 증가 확인
- 5Scale In 테스트: 부하 제거 후 5~10분 대기 → 인스턴스 수가 다시 2대로 감소하는지 확인
- 6대상 그룹 상태 확인: EC2 콘솔 → 대상 그룹 → inspection-tg → 대상 탭에서 모든 인스턴스가 "healthy" 상태인지 확인
트러블슈팅
ALB DNS로 접속했는데 페이지가 안 뜨는 경우:
- ALB 상태가 Active인지 확인합니다 (provisioning이면 1~2분 대기)
- 대상 그룹에서 인스턴스 상태가 healthy인지 확인합니다
- ALB 보안 그룹에 HTTP(80) 인바운드가 있는지 확인합니다
- ALB와 인스턴스가 같은 VPC, 같은 서브넷에 있는지 확인합니다
대상 그룹에서 인스턴스가 "unhealthy"인 경우:
- EC2에 SSH 접속하여
curl http://localhost가 응답하는지 확인합니다 - httpd 서비스가 실행 중인지 확인:
systemctl status httpd - EC2 보안 그룹에서 ALB 보안 그룹으로부터의 HTTP(80) 인바운드가 허용되어 있는지 확인합니다
- Health Check 경로가
/로 올바르게 설정되어 있는지 확인합니다
Auto Scaling이 동작하지 않는 경우:
- CloudWatch 콘솔에서 ASG 관련 경보가 생성되어 있는지 확인합니다
- ASG의 최대 용량이 최소 용량보다 큰지 확인합니다
- 크기 조정 정책이 올바르게 설정되어 있는지 확인합니다
- 시작 템플릿에서 서브넷에 여유 IP가 있는지 확인합니다
새로고침해도 같은 인스턴스만 표시되는 경우:
- 브라우저 캐시를 삭제하거나 시크릿 모드를 사용합니다
curl http://<ALB-DNS>명령어를 여러 번 실행해 봅니다- ALB의 Sticky Session(세션 고정)이 활성화되어 있지 않은지 확인합니다
- 대상 그룹에 인스턴스가 2대 이상 등록되어 있는지 확인합니다
확장 아이디어
이 실습을 마쳤다면, 다음 단계로 도전해 보세요:
- HTTPS 적용: ACM에서 SSL 인증서를 발급받아 ALB에 HTTPS 리스너를 추가하고, HTTP → HTTPS 리다이렉트를 설정해 보세요.
- 커스텀 Health Check 페이지:
/health엔드포인트를 만들어 DB 연결 상태, 디스크 용량 등을 검사하는 상세한 Health Check를 구현해 보세요. - 예약된 스케일링: 교대 근무 시간표에 맞춰 특정 시간에 인스턴스를 미리 늘려두는 예약 스케일링을 설정해 보세요.
- 다중 대상 그룹: 경로 기반 라우팅으로
/api/*요청은 다른 대상 그룹으로 보내는 구성을 만들어 보세요 (다음 미니 프로젝트의 사전 준비!). - CloudWatch 대시보드: ALB 요청 수, 대상 응답 시간, 건강한 호스트 수를 한 눈에 볼 수 있는 대시보드를 만들어 보세요.
다음 단계 미리보기
이 인프라는 삭제하지 마세요! 다음 미니 프로젝트 "설비 점검 요청 관리 API"에서 이 EC2 위에 FastAPI 백엔드를 올려 실제 점검 요청 CRUD 기능을 구현합니다. 지금 만든 ALB + Auto Scaling 인프라가 그대로 재사용됩니다.
학습 정리
핵심 치트시트
이 프로젝트에서는 VPC, ALB, EC2, Auto Scaling Group을 조합하여 24시간 운영 가능한 고가용 점검 포털을 구축했습니다. 핵심은 다중 AZ 배치, ALB의 Health Check, ASG의 자동 복구 및 확장입니다.
리소스 정리
다음 미니 프로젝트를 바로 진행하지 않는다면, 아래 순서대로 리소스를 정리하세요. ASG를 먼저 삭제해야 EC2가 자동으로 다시 생성되지 않습니다.
- Auto Scaling Group 삭제 (인스턴스가 자동 종료됨)
- 시작 템플릿 삭제
- 로드 밸런서(ALB) 삭제
- 대상 그룹 삭제
- 보안 그룹 삭제 (ALB용, EC2용)
- VPC 삭제 (연결된 서브넷, IGW, 라우팅 테이블이 함께 삭제됨)