왜 이걸 만들까? — 데이터가 사일로에 갇혀 있다면
여러분이 이커머스 회사의 데이터 분석가라고 상상해 보세요.
마케팅팀은 구글 애널리틱스 데이터를 CSV로 내보내고, 물류팀은 배송 기록을 엑셀로 관리하며, 재무팀은 ERP 시스템에서 매출 데이터를 별도로 뽑아 씁니다. "이번 달 카테고리별 매출과 마케팅 비용 대비 수익률을 알고 싶어요"라는 CEO의 질문에 답하려면, 3개 팀에 각각 데이터를 요청하고, 엑셀에서 VLOOKUP으로 합치고, 피벗 테이블을 만들어야 합니다. 이 과정만 이틀이 걸립니다.
데이터 레이크(Data Lake)는 이 문제를 해결합니다.
모든 부서의 데이터를 하나의 중앙 저장소(S3)에 원본 그대로 모으고, 자동화된 파이프라인으로 분석 가능한 형태로 변환한 뒤, SQL 한 줄로 누구나 필요한 인사이트를 뽑아낼 수 있게 합니다.
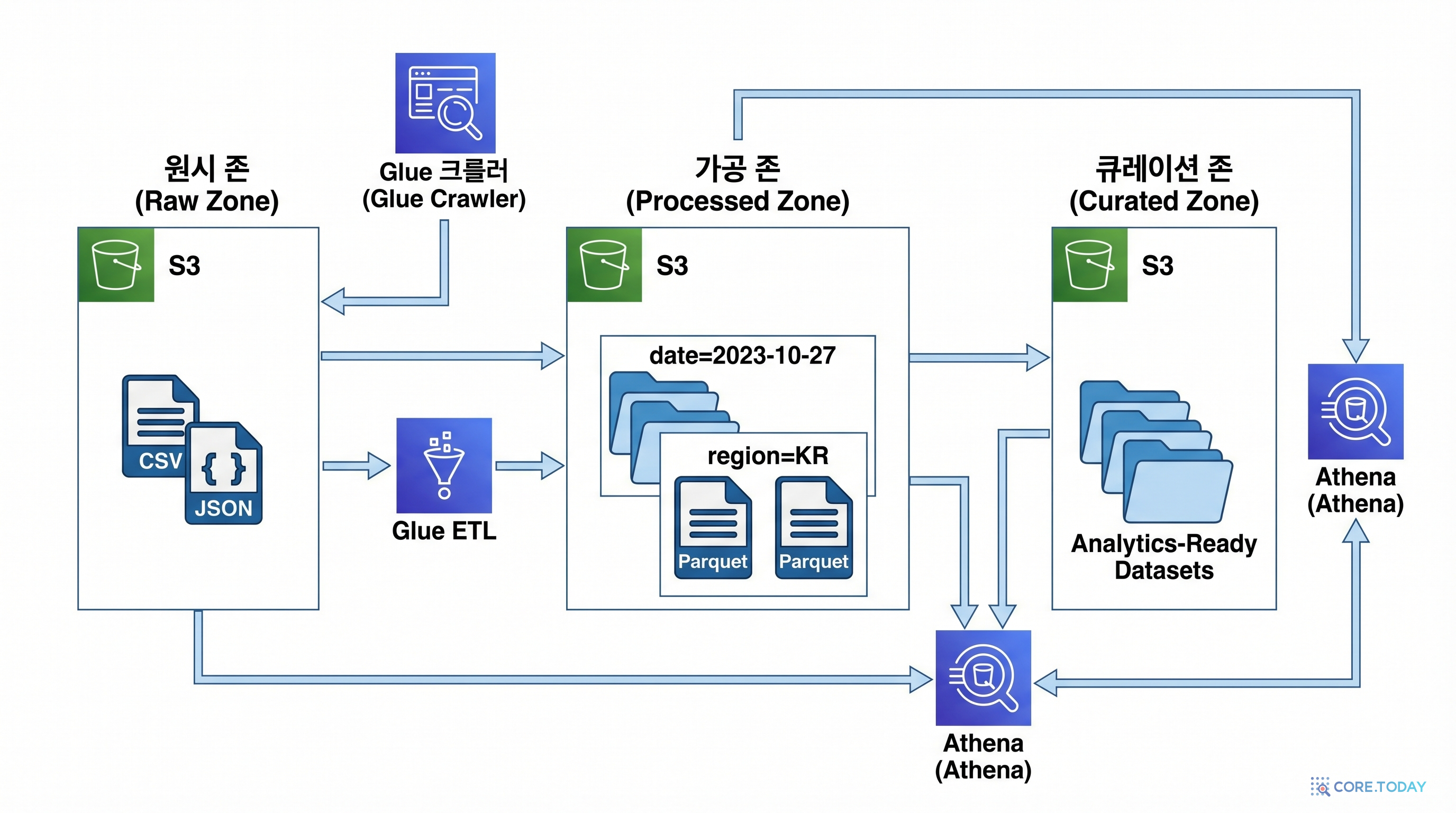
이 실습에서는 AWS의 서버리스 데이터 서비스를 조합하여 미니 데이터 레이크를 구축합니다:
- S3: 원본 CSV를 저장하는 Raw Zone과 변환된 Parquet를 저장하는 Processed Zone
- Glue Crawler: 데이터의 스키마(컬럼명, 타입)를 자동으로 탐지
- Glue ETL Job: CSV를 고성능 Parquet 형식으로 자동 변환
- Athena: S3에 저장된 데이터를 SQL로 직접 쿼리 (서버 설치 불필요!)
완성하면 "카테고리별 매출 합계"를 SQL 한 줄로 수 초 만에 뽑을 수 있습니다.
이 프로젝트를 통해 배우게 되는 것:
- 데이터 레이크 설계 패턴: Raw/Processed Zone 분리의 이유와 방법
- 스키마 자동 탐지: Glue Crawler가 데이터 구조를 어떻게 추론하는지
- 데이터 형식 최적화: CSV → Parquet 변환이 비용에 미치는 영향
- 서버리스 SQL 분석: Athena로 서버 설치 없이 SQL 쿼리하는 방법
- 파티셔닝 전략: 데이터를 폴더로 분리하여 쿼리 성능을 높이는 기법
실습을 시작하기 전에 AWS 콘솔에 로그인되어 있는지 확인하세요. 리전은 ap-northeast-2 (서울) 을 사용합니다.
아키텍처 개요

데이터 파이프라인 흐름
비용 예측
비용 계산기
DPU/시간
DPU/시간
스캔 TB
GB/월
* 실제 비용은 AWS 요금 정책에 따라 달라질 수 있습니다.
Step 1: S3 버킷 구조 생성
데이터 레이크의 물리적 기반은 S3 버킷입니다. 데이터의 생명주기에 따라 폴더(접두사)를 나누는 것이 핵심입니다. Raw Zone에는 원본 데이터를 그대로 보관하고, Processed Zone에는 분석에 최적화된 형태로 변환한 데이터를 저장합니다. 이렇게 분리하면 원본이 항상 보존되어, 변환 로직에 문제가 생겨도 언제든 다시 처리할 수 있습니다.
- S3 콘솔 → 버킷 만들기 → 이름:
datalake-lab-{계정ID}(전역적으로 고유해야 함) - 리전: 아시아 태평양(서울) 확인, 나머지 설정은 기본값 유지
- 버킷 생성 후 다음 폴더 구조 생성:
raw/sales/— 원본 CSV 데이터processed/sales/— 변환된 Parquet 데이터athena-results/— Athena 쿼리 결과 저장
- 각 폴더 경로에 폴더 만들기 클릭하여 생성 (중첩 폴더도 한 번에 지정 가능)
- 각 폴더가 S3 콘솔에서 보이는지 확인 — S3의 "폴더"는 실제로는
/로 끝나는 빈 객체(prefix)입니다
aws s3 mb s3://datalake-lab-ACCOUNT_ID
aws s3api put-object --bucket datalake-lab-ACCOUNT_ID --key raw/sales/
aws s3api put-object --bucket datalake-lab-ACCOUNT_ID --key processed/sales/
aws s3api put-object --bucket datalake-lab-ACCOUNT_ID --key athena-results/데이터 레이크는 일반적으로 Raw → Staging → Processed 3단계 존으로 구성합니다. Raw Zone은 원본을 그대로 보관(변경 불가), Staging은 클렌징/변환 중간 결과, Processed는 분석 최적화된 최종 데이터입니다. 이 실습에서는 간소화를 위해 Raw와 Processed 2단계만 사용합니다.
버킷 이름 규칙: S3 버킷 이름은 전 세계적으로 고유해야 하며, 소문자, 숫자, 하이픈만 사용 가능합니다. 언더스코어(_)나 대문자는 사용할 수 없습니다. 이름이 이미 사용 중이면 생성이 실패하므로, 계정 ID를 접미사로 붙여 고유성을 확보하세요.
Step 2: 샘플 CSV 데이터 업로드
실습에 사용할 매출 데이터 CSV 파일을 만들어 업로드합니다. 실제 기업 데이터와 유사한 구조를 갖추되, 카테고리가 다양해야 이후 집계 쿼리 결과가 의미 있습니다. 데이터가 너무 적으면 Glue Crawler가 스키마를 잘못 추론할 수 있으니 최소 5건 이상 넣으세요.
- 1로컬 PC에서 텍스트 에디터를 열고 sales_data.csv 파일 생성
- 2첫 줄에 헤더 입력: order_id,product,category,quantity,price,order_date
- 3아래 예시처럼 10건의 샘플 데이터 추가 (카테고리를 3개 이상으로 분산): 1001,무선 마우스,전자기기,2,25000,2024-01-15 1002,USB-C 허브,주변기기,1,45000,2024-01-16 1003,외장 SSD 1TB,저장장치,3,89000,2024-01-17 ... (7건 더 추가)
- 4파일을 UTF-8 인코딩으로 저장 (한글 깨짐 방지)
- 5S3 콘솔 → datalake-lab-{계정ID} → raw/sales/ 경로로 이동 → 업로드 클릭
- 6sales_data.csv 파일 선택 → 업로드 완료
- 7파일이 raw/sales/sales_data.csv 경로에 정상 저장되었는지 확인
CSV 인코딩 주의: Windows에서 엑셀로 저장하면 기본적으로 EUC-KR 인코딩이 적용되어 Glue에서 한글이 깨질 수 있습니다.
반드시 UTF-8 인코딩으로 저장하세요. 메모장에서는 "다른 이름으로 저장" → 인코딩: UTF-8을 선택합니다.
중간 점검
지금까지의 진행 상황을 확인합니다:
- S3 버킷
datalake-lab-{계정ID}가 생성되었는지 raw/sales/,processed/sales/,athena-results/폴더가 존재하는지raw/sales/sales_data.csv파일이 업로드되어 있는지- CSV 파일을 클릭하여 "데이터 미리보기"로 한글이 깨지지 않는지
여기까지 완료되었으면, 이제 Glue가 이 데이터를 자동으로 분석하는 단계로 넘어갑니다.
데이터 웨어하우스 vs 데이터 레이크
이 실습을 진행하면서 "데이터 웨어하우스(DW)와 무엇이 다른가?"라는 의문이 들 수 있습니다. 핵심 차이를 이해해 두면 아키텍처 선택에 도움이 됩니다.
| 비교 항목 | 데이터 웨어하우스 | 데이터 레이크 |
|---|---|---|
| 스키마 적용 시점 | 저장 시 (Schema-on-Write) | 읽기 시 (Schema-on-Read) |
| 데이터 형식 | 구조화된 데이터만 | 구조화/반구조화/비구조화 모두 |
| 저장소 | 전용 DB (Redshift 등) | S3 (범용 스토리지) |
| 비용 | 높음 (항상 서버 가동) | 낮음 (저장 비용만 발생) |
| 사용 목적 | 정형 보고서, BI | 탐색적 분석, ML, 로그 분석 |
| AWS 서비스 | Redshift | S3 + Glue + Athena |
이 실습에서 구축하는 것은 S3 기반 데이터 레이크입니다. 별도 서버 없이 필요할 때만 Athena로 쿼리하면 되므로 비용이 매우 저렴합니다.
Step 3: Glue Crawler로 스키마 자동 탐지
Glue Crawler는 S3에 저장된 데이터 파일을 스캔하여 컬럼명, 데이터 타입, 파일 형식을 자동으로 추론합니다. 추론한 결과를 Glue Data Catalog에 테이블로 등록하면, 이후 Athena나 Redshift Spectrum에서 SQL로 바로 쿼리할 수 있습니다. 수동으로 CREATE TABLE 문을 작성할 필요가 없어 대량의 데이터 소스를 빠르게 카탈로깅할 수 있습니다.
- Glue 콘솔 → 좌측 메뉴 → 크롤러 → 크롤러 추가
- 크롤러 이름:
sales-raw-crawler - 데이터 소스: S3 → 경로:
s3://datalake-lab-{계정ID}/raw/sales/ - IAM 역할: 새 IAM 역할 생성 → 이름:
AWSGlueServiceRole-lab(S3 읽기 권한 자동 포함) - 데이터베이스: 데이터베이스 추가 → 이름:
datalake_lab_db - 테이블 접두사:
raw_입력 (테이블명이raw_sales가 됨) - 크롤러 생성 완료 후 → 크롤러 실행 클릭 → 완료 대기 (약 1~2분)
- Glue → 테이블 메뉴에서
raw_sales테이블이 생성되었는지 확인 - 테이블 클릭 → 스키마 탭에서 각 컬럼의 이름과 데이터 타입(string, bigint 등) 확인
- 컬럼 수가 CSV 헤더와 일치하는지 확인 — order_id, product, category, quantity, price, order_date 총 6개
aws glue create-database \
--database-input '{"Name":"datalake_lab_db"}'
aws glue create-crawler \
--name sales-raw-crawler \
--role AWSGlueServiceRole-lab \
--database-name datalake_lab_db \
--table-prefix raw_ \
--targets '{"S3Targets":[{"Path":"s3://datalake-lab-ACCOUNT_ID/raw/sales/"}]}'
aws glue start-crawler --name sales-raw-crawlerCrawler가 스키마를 잘못 추론할 때: CSV 데이터가 너무 적거나 형식이 불규칙하면 quantity 컬럼이 string으로 감지될 수 있습니다. 이 경우 Glue 콘솔 → 테이블 → 스키마 편집에서 수동으로 bigint이나 double로 변경하세요. 또는 CSV의 숫자 컬럼에 따옴표가 감싸져 있지 않은지 확인하세요.
Step 4: Glue ETL Job으로 Parquet 변환
CSV는 사람이 읽기 편하지만, 분석에는 비효율적입니다. Parquet은 열 기반(Columnar) 저장 방식으로, 특정 컬럼만 조회할 때 다른 컬럼 데이터를 읽지 않아도 됩니다. 또한 데이터 타입에 맞는 효율적인 압축이 자동으로 적용됩니다. Glue ETL Job은 이 변환을 자동으로 수행합니다.
- 1Glue 콘솔 → ETL 작업 → Visual ETL 선택 (시각적 편집 모드)
- 2스크립트 편집기 탭으로 전환 → 작업 이름: csv-to-parquet-job
- 3작업 세부 정보 → IAM 역할: AWSGlueServiceRole-lab 선택
- 4Glue 버전: 4.0 선택, Worker 유형: G.1X (최소 사양), Worker 수: 2 (실습용)
- 5소스 설정: Data Catalog → 데이터베이스 datalake_lab_db → 테이블 raw_sales 선택
- 6변환 추가: 형식 변경 → 출력 형식 Parquet 선택, 압축: Snappy (기본값)
- 7대상 설정: S3 → 경로: s3://datalake-lab-{계정ID}/processed/sales/
- 8파티션 키: category 추가 (카테고리별 폴더가 자동 분리됨: category=전자기기/, category=주변기기/ 등)
- 9저장 후 실행 클릭 → 완료 대기 (약 2~3분)
- 10S3 콘솔에서 processed/sales/ 경로를 확인 → 카테고리별 하위 폴더와 .parquet 파일 생성 확인
Parquet 형식은 열 기반(columnar) 저장 방식으로 특정 컬럼만 조회할 때 스캔 데이터량이 크게 줄어 Athena 쿼리 비용이 절감됩니다. CSV 대비 최대 30~90% 스토리지와 쿼리 비용을 절약할 수 있습니다.
본인의 말로 설명해 보세요
동료에게 'CSV 대신 Parquet을 사용하면 왜 Athena 쿼리 비용이 줄어드는지'를 도서관에서 책 찾는 비유로 설명해 보세요.
Step 5: Athena로 데이터 쿼리
Athena는 S3에 저장된 데이터를 서버 설치 없이 SQL로 직접 쿼리할 수 있는 서버리스 서비스입니다. 스캔한 데이터 1TB당 $5가 과금되므로, Parquet + 파티션 구조가 비용 절감에 얼마나 효과적인지 직접 비교해 볼 수 있습니다.
- 1Athena 콘솔 → 쿼리 편집기 열기
- 2처음 사용 시 설정 → 쿼리 결과 위치: s3://datalake-lab-{계정ID}/athena-results/ 입력 후 저장
- 3좌측에서 데이터베이스: datalake_lab_db 선택 → raw_sales 테이블이 보이는지 확인
- 4전체 조회 쿼리 실행: SELECT * FROM raw_sales LIMIT 10; → 결과와 스캔된 데이터 크기 기록
- 5카테고리별 매출 집계: SELECT category, SUM(quantity * price) AS total_sales FROM raw_sales GROUP BY category ORDER BY total_sales DESC;
- 6Processed Zone의 Parquet 테이블도 Crawler로 등록한 뒤 동일 쿼리 실행 → 스캔된 데이터 크기 비교
- 7파티션 필터 테스트: SELECT * FROM processed_sales WHERE category = '전자기기'; → 스캔량이 줄어드는지 확인
핵심 개념 확인
트러블슈팅 가이드
Crawler 실행 후 테이블이 생성되지 않을 때:
- S3 경로가 정확한지 확인:
s3://버킷명/raw/sales/(마지막 슬래시 포함) - CSV 파일이 해당 경로에 실제로 존재하는지 확인
- Crawler의 IAM 역할에 S3 읽기 권한이 있는지 확인 —
AWSGlueServiceRole정책에 해당 버킷이 포함되어야 함
Athena 쿼리 시 "Access Denied" 에러:
- 쿼리 결과 저장 위치(
athena-results/)가 설정되어 있는지 확인 - 사용 중인 IAM 사용자/역할에 S3 읽기 및 Glue Data Catalog 접근 권한이 있는지 확인
- 쿼리 결과 S3 경로에 쓰기 권한이 있는지 확인
Glue ETL Job 실행 실패:
- Worker 수와 DPU 설정이 적절한지 확인 (최소 2 Worker)
- IAM 역할에 소스(S3 Raw)와 대상(S3 Processed) 모두에 대한 권한이 있는지 확인
- Job 실행 로그는 CloudWatch →
/aws-glue/jobs/error로그 그룹에서 확인 가능
본인의 말로 설명해 보세요
데이터 분석을 처음 접하는 마케팅 팀원에게 'Glue Data Catalog이 왜 필요한지, 없으면 어떤 문제가 생기는지'를 도서관 카드 카탈로그 비유로 설명해 보세요.
완성 후 테스트 가이드
전체 파이프라인이 정상 동작하는지 아래 체크리스트로 검증하세요:
- Raw Zone 확인: S3
raw/sales/경로에 원본 CSV 파일이 존재하는지 - Data Catalog 확인: Glue → 테이블에서
raw_sales의 스키마가 CSV 헤더와 일치하는지 - Parquet 변환 확인: S3
processed/sales/경로에.parquet파일이 카테고리별 폴더에 생성되었는지 - SQL 쿼리 성공: Athena에서
SELECT * FROM raw_sales LIMIT 5;실행 시 데이터가 정상 반환되는지 - 집계 쿼리 성공: 카테고리별 매출 합계 쿼리가 올바른 결과를 반환하는지
- 비용 비교: CSV 테이블 vs Parquet 테이블에서 동일 쿼리의 "스캔된 데이터" 크기 차이 기록
- 파티션 필터 효과:
WHERE category = '전자기기'조건 쿼리의 스캔량이 전체 조회보다 줄어드는지 확인 - Glue 비용 확인: Glue 콘솔 → ETL 작업 → 실행 기록에서 DPU 사용 시간 확인
Athena 유용한 쿼리 모음
실습에서 활용할 수 있는 다양한 분석 쿼리를 정리합니다:
-- 1. 전체 매출 합계
SELECT SUM(quantity * price) AS total_revenue FROM raw_sales;
-- 2. 카테고리별 매출 순위
SELECT category, SUM(quantity * price) AS revenue,
RANK() OVER (ORDER BY SUM(quantity * price) DESC) AS rank
FROM raw_sales GROUP BY category;
-- 3. 일별 주문 건수 추이
SELECT order_date, COUNT(*) AS order_count
FROM raw_sales GROUP BY order_date ORDER BY order_date;
-- 4. 평균 단가가 가장 높은 카테고리
SELECT category, AVG(price) AS avg_price
FROM raw_sales GROUP BY category ORDER BY avg_price DESC LIMIT 1;
-- 5. Parquet 테이블의 파티션 필터 (비용 절감 효과 체감)
SELECT * FROM processed_sales WHERE category = '전자기기';각 쿼리를 실행할 때마다 "스캔된 데이터" 크기를 기록하여 CSV vs Parquet의 비용 차이를 비교해 보세요.
확장 아이디어
- 스케줄링 자동화: EventBridge 규칙으로 Glue Crawler와 ETL Job을 매일 자정에 자동 실행하도록 스케줄링
- 데이터 품질 검증: Glue Data Quality 룰을 추가하여
price > 0,quantity > 0등 데이터 유효성 자동 검증 - Lake Formation 접근 제어: AWS Lake Formation으로 테이블/컬럼 단위 세분화된 접근 권한 관리
- QuickSight 대시보드 연결: Amazon QuickSight를 Athena에 연결하여 매출 추이 시각화 대시보드 구축
- 멀티 소스 통합: 마케팅 데이터(JSON), 물류 데이터(CSV)를 추가 업로드하고 Athena JOIN 쿼리로 크로스 분석
실습 후 사고 실험
이 실습에서는 10건의 CSV 데이터를 사용했습니다. 하지만 실제 기업 환경에서는 어떨까요?
시나리오 1: 데이터가 1억 건이라면?
- S3에 1TB의 CSV 데이터가 있다면, Athena로 전체 스캔 시 비용은 $5/쿼리
- Parquet으로 변환하면 300GB로 압축 → 같은 쿼리가 $1.5/쿼리
- category 파티셔닝 + 특정 카테고리만 조회하면 → $0.15/쿼리 (10배 절감!)
시나리오 2: 매일 새로운 데이터가 추가된다면?
- EventBridge로 매일 자정에 Glue Crawler + ETL Job을 자동 실행
- 날짜(order_date) 기반 파티셔닝을 추가하면 최근 데이터만 효율적으로 조회
- S3 수명 주기 정책으로 90일 이상 된 데이터를 Glacier로 자동 이전하여 스토리지 비용 90% 절감
시나리오 3: 여러 부서가 같은 데이터를 사용한다면?
- AWS Lake Formation으로 테이블/컬럼 단위 접근 제어
- 마케팅팀은 매출 데이터만, 물류팀은 배송 데이터만 접근 허용
- 모든 쿼리 이력이 CloudTrail에 자동 기록되어 감사 추적 가능
이런 확장 시나리오를 머릿속에 그려보면, 데이터 레이크의 실질적 가치를 더 깊이 이해할 수 있습니다.
학습 정리
핵심 치트시트
S3, Glue, Athena를 조합한 서버리스 데이터 레이크를 구축했습니다. S3에 원본 CSV를 저장하고, Glue Crawler로 스키마를 자동 탐지하여 Data Catalog에 등록한 뒤, Glue ETL Job으로 Parquet 형식으로 변환했습니다. 최종적으로 Athena에서 SQL 쿼리로 데이터를 분석하고, CSV vs Parquet의 비용 차이를 직접 확인했습니다.
핵심 개념
- •데이터 레이크 (Data Lake) — 다양한 소스의 데이터를 원본 형태 그대로 중앙 저장소에 모으는 아키텍처. 스키마를 미리 정의하지 않고(Schema-on-Read), 데이터를 읽는 시점에 스키마를 적용합니다. S3가 AWS 데이터 레이크의 표준 저장소입니다.
- •Glue Crawler — S3, JDBC 등 데이터 소스를 스캔하여 파일 형식, 스키마(컬럼명/타입), 파티션 구조를 자동 탐지하고 Glue Data Catalog에 테이블로 등록하는 서비스. CREATE TABLE DDL을 수동으로 작성할 필요가 없습니다.
- •Glue Data Catalog — 데이터 레이크의 메타데이터(테이블, 스키마, 파티션 정보)를 저장하는 중앙 메타스토어. Athena, Redshift Spectrum, EMR 등 여러 분석 서비스가 이 카탈로그를 공유하여 참조합니다.
- •Parquet — Apache 프로젝트의 열 기반(Columnar) 파일 형식. 컬럼별로 데이터를 저장하므로 특정 컬럼만 조회할 때 불필요한 데이터를 읽지 않습니다. 높은 압축률과 인코딩 효율로 스토리지/쿼리 비용을 30~90% 절감합니다.
- •파티셔닝 (Partitioning) — 데이터를 특정 컬럼 값(예: category, date)에 따라 하위 폴더로 분리 저장하는 기법. Athena가 쿼리 조건에 맞는 폴더만 스캔하므로(Partition Pruning) 비용과 속도가 크게 개선됩니다.
- •Athena — S3에 저장된 데이터를 표준 SQL로 쿼리하는 서버리스 분석 서비스. 서버 설치/관리가 불필요하고, 스캔된 데이터량(TB)에 따라 과금됩니다. Glue Data Catalog를 메타스토어로 사용합니다.
흔한 실수
- CSV 파일을 EUC-KR로 저장하여 Glue/Athena에서 한글이 깨짐 — 반드시 UTF-8로 저장
- Crawler IAM 역할에 S3 버킷 접근 권한이 누락되어 테이블이 생성되지 않음
- Athena 쿼리 결과 저장 위치를 설정하지 않아 첫 쿼리에서 에러 발생
- ETL Job에서 파티션 키를 설정하지 않아 전체 스캔 쿼리만 가능
- Glue ETL Job 실행 후 Processed Zone에 대해 Crawler를 다시 실행하지 않아 Athena에서 테이블 미등록
- 실습 완료 후 Glue ETL Job과 Crawler를 삭제하지 않아 예상치 못한 과금
| CSV (행 기반 저장) | Parquet (열 기반 저장) |
|---|---|
| 전체 행을 순서대로 저장 | 각 컬럼을 별도로 저장 |
| 특정 컬럼 조회 시 전체 행을 읽어야 함 | 필요한 컬럼만 선택적으로 읽기 가능 |
| 압축 효율이 낮음 (혼합된 데이터 타입) | 같은 타입끼리 저장하여 높은 압축률 |
| 사람이 읽기 쉬움 (텍스트 에디터) | 바이너리 형식으로 사람이 읽기 어려움 |
| Athena 스캔량 多 = 비용 高 | Athena 스캔량 少 = 비용 低 |
리소스 정리
실습 완료 후 반드시 아래 순서대로 리소스를 정리하여 불필요한 과금을 방지하세요.
- Glue ETL 작업 삭제 (
csv-to-parquet-job) - Glue Crawler 삭제 (
sales-raw-crawler) - Glue Data Catalog 테이블 삭제 (
raw_sales) - Glue 데이터베이스 삭제 (
datalake_lab_db) - S3 버킷 비우기 및 삭제 (
datalake-lab-{계정ID}) - IAM 역할 삭제 (
AWSGlueServiceRole-lab) - Athena 저장된 쿼리 삭제 (있는 경우)