왜 로드 밸런서와 Auto Scaling이 필요할까?
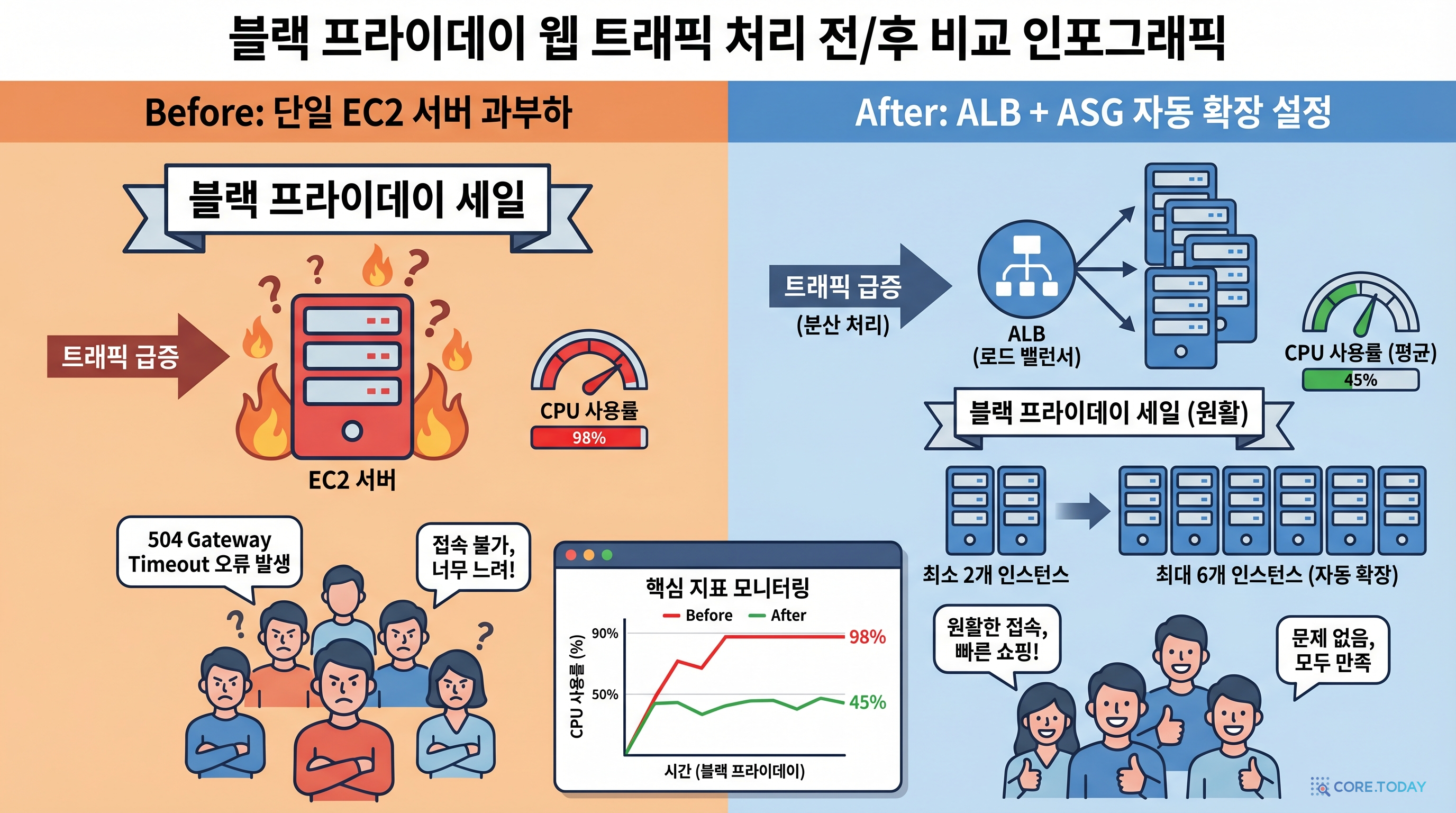
여러분의 웹 서비스가 뉴스에 소개되었다고 상상해 보세요. 평소 100명이던 동시 접속자가 갑자기 10,000명으로 늘어납니다.
서버 한 대로는 감당이 안 됩니다. 순간적으로 응답 시간이 10초를 넘기고, 결국 서버가 다운됩니다. 사용자들은 "사이트가 안 열린다"며 이탈하기 시작합니다.
이런 상황을 어떻게 해결할 수 있을까요?
Application Load Balancer(ALB)는 들어오는 트래픽을 여러 서버에 골고루 분배하는 교통 정리 경찰입니다. Auto Scaling Group(ASG)은 트래픽에 따라 서버 수를 자동으로 늘리고 줄이는 자동 증원/감축 시스템입니다.
이 두 가지를 조합하면:
- 사용자가 많아지면 → 서버가 자동으로 늘어나고 → ALB가 트래픽을 분배
- 사용자가 줄어들면 → 불필요한 서버가 자동으로 제거 → 비용 절감
실무에서는 거의 모든 프로덕션 웹 서비스가 이 구성을 사용합니다. 서버 한 대가 다운되어도 다른 서버들이 트래픽을 처리하므로 고가용성이 확보됩니다.
이 실습을 마치면 여러분은:
- ALB로 트래픽을 분산하는 방법을 알게 됩니다
- Auto Scaling으로 서버를 자동 확장/축소하는 방법을 알게 됩니다
- 실제로 부하 테스트를 통해 Scale Out이 동작하는 것을 직접 확인합니다
실습을 시작하기 전에 VPC 네트워크 설계 실습을 완료하고, 퍼블릭/프라이빗 서브넷이 구성된 VPC가 준비되어 있어야 합니다. 리전은 ap-northeast-2 (서울) 을 사용합니다.
아키텍처 개요
트래픽 흐름
비용 예측
비용 계산기
시간
시간
GB
* 실제 비용은 AWS 요금 정책에 따라 달라질 수 있습니다.
Step 1: Launch Template 생성
Launch Template은 Auto Scaling이 새 인스턴스를 생성할 때 사용하는 설계도입니다. "어떤 AMI를 사용할지, 인스턴스 타입은 뭔지, 보안 그룹은 뭔지, 시작 스크립트는 뭔지"를 미리 정의해 둡니다.
특히 사용자 데이터(User Data) 스크립트가 중요합니다. 인스턴스가 시작될 때 자동으로 웹 서버를 설치하고 실행하는 스크립트를 넣습니다. Auto Scaling으로 새 인스턴스가 추가될 때마다 사람의 개입 없이 바로 서비스가 가능해야 하기 때문입니다.
- EC2 콘솔 → 좌측 시작 템플릿 → 시작 템플릿 생성 클릭
- 시작 템플릿 이름:
lab-web-template - 애플리케이션 및 OS 이미지: Amazon Linux 2023 AMI 선택 (무료 티어)
- 인스턴스 유형:
t3.micro선택 - 키 페어: 기존 키 페어 선택 또는 새로 생성 (SSH 접속용)
- 네트워크 설정: 보안 그룹 선택하지 않음 (ASG에서 설정합니다)
- 고급 세부 정보 확장 → 맨 아래 사용자 데이터에 아래 스크립트 입력:
#!/bin/bash
yum update -y
yum install -y httpd stress
INSTANCE_ID=$(ec2-metadata -i | cut -d' ' -f2)
cat > /var/www/html/index.html << HTMLEOF
<!DOCTYPE html>
<html><body>
<h1>Hello from $INSTANCE_ID</h1>
<p>Instance: $INSTANCE_ID</p>
<p>AZ: $(ec2-metadata -z | cut -d' ' -f2)</p>
</body></html>
HTMLEOF
systemctl start httpd
systemctl enable httpd
- 시작 템플릿 생성 클릭
aws ec2 create-launch-template \
--launch-template-name lab-web-template \
--launch-template-data '{
"ImageId":"ami-0c55b159cbfafe1f0","InstanceType":"t3.micro",
"SecurityGroupIds":["sg-xxxxxxxx"],
"UserData":"IyEvYmluL2Jhc2gKeXVtIHVwZGF0ZSAteQp5dW0gaW5zdGFsbCAteSBodHRwZCBzdHJlc3M="
}'resource "aws_launch_template" "web" {
name = "lab-web-template"
image_id = data.aws_ami.amazon_linux.id
instance_type = "t3.micro"
user_data = base64encode(<<-EOF
#!/bin/bash
yum update -y
yum install -y httpd stress
systemctl start httpd
systemctl enable httpd
EOF
)
}사용자 데이터 스크립트에서 인스턴스 ID와 AZ를 HTML에 포함시키면, 나중에 브라우저에서 새로고침할 때 어떤 인스턴스가 응답하는지 쉽게 확인할 수 있습니다. 로드 밸런싱이 잘 동작하는지 눈으로 확인하는 좋은 방법입니다.
Step 2: ALB 및 Target Group 생성
ALB(Application Load Balancer)는 Layer 7(HTTP/HTTPS)에서 동작하는 로드 밸런서입니다. URL 경로, 호스트 헤더, HTTP 메서드 등을 기반으로 트래픽을 라우팅할 수 있습니다.
Target Group은 ALB가 트래픽을 보낼 대상(EC2 인스턴스들)의 그룹입니다. ALB는 Target Group 안의 인스턴스들에게 순차적으로 요청을 분배합니다.
헬스 체크는 특히 중요합니다. ALB는 주기적으로 각 인스턴스에 HTTP 요청을 보내고, 정상 응답(200 OK)을 받지 못하면 해당 인스턴스로 트래픽을 보내지 않습니다. 장애가 발생한 서버에 사용자 요청이 전달되는 것을 자동으로 방지해 줍니다.
- 1EC2 콘솔 → 좌측 로드밸런서 → 로드 밸런서 생성 클릭
- 2Application Load Balancer 선택 → 생성 클릭
- 3기본 구성: 이름: lab-alb 체계(Scheme): 인터넷 경계(Internet-facing) 선택 IP 주소 유형: IPv4 선택
- 4네트워크 매핑: VPC: lab-vpc 선택 매핑에서 ap-northeast-2a와 ap-northeast-2c 체크 각 AZ에서 퍼블릭 서브넷 선택 (lab-public-a, lab-public-b)
- 5보안 그룹: 기본 보안 그룹 제거 → HTTP(80) 인바운드를 허용하는 보안 그룹 선택 없다면 새로 생성: 이름 lab-alb-sg, 인바운드 HTTP(80) 0.0.0.0/0 허용
- 6리스너 및 라우팅: 프로토콜: HTTP, 포트: 80 대상 그룹 생성 링크 클릭 (새 탭에서 열림)
- 7대상 그룹 생성 (새 탭): 대상 유형: 인스턴스 선택 이름: lab-tg 프로토콜/포트: HTTP / 80 VPC: lab-vpc 선택 헬스 체크 경로: / (기본값) 고급 헬스 체크 설정: 정상 임계값 2, 비정상 임계값 3, 타임아웃 5초, 간격 30초 다음 → 대상은 등록하지 않고 대상 그룹 생성 클릭
- 8ALB 생성 탭으로 돌아와서 → 대상 그룹 새로고침 → lab-tg 선택
- 9로드 밸런서 생성 클릭
- 10프로비저닝에 2~3분이 소요됩니다. 상태가 Active가 될 때까지 기다립니다.
흔한 실수: ALB의 서브넷으로 프라이빗 서브넷을 선택하는 경우. Internet-facing ALB는 반드시 퍼블릭 서브넷에 배치해야 합니다. 프라이빗 서브넷에 배치하면 외부에서 접근할 수 없습니다.
Step 3: Auto Scaling Group 설정
Auto Scaling Group은 EC2 인스턴스의 수를 자동으로 관리합니다. 최소/최대/희망 용량을 설정하고, 조건에 따라 인스턴스를 추가(Scale Out)하거나 제거(Scale In)합니다.
- EC2 콘솔 → 좌측 Auto Scaling 그룹 → Auto Scaling 그룹 생성 클릭
- 1단계 - 시작 템플릿 선택:
- 이름:
lab-asg - 시작 템플릿:
lab-web-template선택 - 버전: Latest 선택
- 다음 클릭
- 이름:
- 2단계 - 인스턴스 시작 옵션 선택:
- VPC:
lab-vpc선택 - 가용 영역 및 서브넷:
lab-private-a,lab-private-b선택 (프라이빗 서브넷!) - 다음 클릭
- VPC:
- 3단계 - 고급 옵션 구성:
- 로드 밸런싱: 기존 로드 밸런서에 연결 선택
- 기존 로드 밸런서 대상 그룹:
lab-tg선택 - 상태 확인: ELB 상태 확인 켜기 체크 (중요!)
- 상태 확인 유예 기간: 300초 (인스턴스 초기화 시간 확보)
- 다음 클릭
- 4단계 - 그룹 크기 및 크기 조정 정책 구성:
- 원하는 용량: 2 (항상 2개 이상 운영)
- 최소 용량: 2
- 최대 용량: 4
- 크기 조정 정책: 대상 추적 크기 조정 정책 선택
- 지표 유형: 평균 CPU 사용률
- 대상 값: 70 (CPU 70% 초과 시 Scale Out)
- 다음 → 다음 → Auto Scaling 그룹 생성 클릭
aws autoscaling create-auto-scaling-group \
--auto-scaling-group-name lab-asg \
--launch-template LaunchTemplateName=lab-web-template,Version='$Latest' \
--min-size 2 --max-size 4 --desired-capacity 2 \
--vpc-zone-identifier "subnet-a,subnet-b" \
--target-group-arns "arn:aws:elasticloadbalancing:..."resource "aws_autoscaling_group" "web" {
name = "lab-asg"
min_size = 2
max_size = 4
desired_capacity = 2
target_group_arns = [aws_lb_target_group.web.arn]
launch_template { id = aws_launch_template.web.id }
}대상 추적 조정 정책은 CloudWatch 경보를 자동으로 생성합니다. CPU 사용률 70%를 초과하면 Scale Out, 안정되면 Scale In이 동작합니다. CloudWatch 콘솔에서 자동 생성된 경보를 확인해 보세요.
EC2 인스턴스가 프라이빗 서브넷에 있는데, 왜 인터넷에서 접근 가능한가요? 사용자 → ALB(퍼블릭 서브넷) → Target Group → EC2(프라이빗 서브넷) 순서로 트래픽이 흐릅니다. 사용자는 ALB의 퍼블릭 DNS로 접속하고, ALB가 프라이빗 서브넷의 EC2로 요청을 전달합니다. EC2에 직접 접근하는 것이 아니므로 보안이 유지됩니다.
Step 4: 동작 확인 — 로드밸런싱 테스트
이제 ALB와 Auto Scaling이 정상적으로 동작하는지 확인합니다.
- 1EC2 콘솔 → 로드밸런서 → lab-alb 선택
- 2설명 탭에서 DNS 이름을 복사합니다 (예: lab-alb-12345.ap-northeast-2.elb.amazonaws.com)
- 3브라우저에서 해당 DNS 이름으로 접속합니다
- 4"Hello from i-xxxxxxxx" 페이지가 표시되면 정상입니다
- 5브라우저를 여러 번 새로고침합니다 → Instance ID가 바뀌면 로드밸런싱이 동작하는 것입니다!
- 6대상 그룹 → lab-tg → Targets 탭에서 2개 인스턴스가 healthy 상태인지 확인합니다
접속이 안 되는 경우 체크리스트:
- ALB 상태가 Active인지 확인 (Provisioning이면 2~3분 대기)
- Target Group의 인스턴스가 healthy 상태인지 확인
- ALB 보안 그룹에 HTTP(80) 인바운드가 허용되어 있는지 확인
- EC2 보안 그룹에 ALB 보안 그룹으로부터 HTTP(80) 인바운드가 허용되어 있는지 확인
Step 5: 부하 테스트 — Scale Out 확인
이 단계에서는 실제로 CPU 부하를 발생시켜 Auto Scaling의 Scale Out을 관찰합니다. 이것이 이 실습의 하이라이트입니다!
- 1인스턴스에 접속: 프라이빗 서브넷의 EC2에 직접 SSH가 안 되므로, 퍼블릭 서브넷에 Bastion Host를 만들거나 SSM Session Manager를 사용합니다
- 2SSM 방법: EC2 콘솔 → 인스턴스 선택 → 연결 → Session Manager 탭 → 연결 (IAM 역할에 SSM 권한 필요)
- 3접속 후 stress 설치 확인: which stress (User Data에서 이미 설치됨)
- 4CPU 부하 시작: stress --cpu 4 --timeout 300 (5분간 CPU 100% 부하)
- 5다른 인스턴스에도 동일하게 접속하여 stress 실행 (두 인스턴스 모두 부하를 걸어야 평균 CPU가 올라감)
- 6CloudWatch 확인: CloudWatch 콘솔 → 경보 → Auto Scaling이 생성한 경보 확인 TargetTracking-lab-asg-AlarmHigh 경보가 In alarm 상태로 변경되는 것을 확인
- 7Scale Out 확인: EC2 → Auto Scaling 그룹 → lab-asg → 활동 탭 "Launching a new EC2 instance" 활동이 표시되면 Scale Out 성공!
- 8Target Group 확인: 새 인스턴스가 Target Group에 자동 등록되고 healthy 상태가 되는지 확인
- 9부하 중단 후(5분 뒤 자동 종료) 약 5~10분 기다리면 Scale In이 동작하여 인스턴스가 줄어듭니다
Scale Out은 비교적 빨리 반응하지만 (12분), Scale In은 의도적으로 느리게 동작합니다 (515분).
이는 트래픽이 다시 증가할 수 있는 상황에서 성급하게 인스턴스를 줄이는 것을 방지하기 위함입니다.
이를 쿨다운(Cooldown) 기간이라고 합니다.
핵심 개념 확인
직접 설명해 보기
본인의 말로 설명해 보세요
회사 동료에게 ALB와 Auto Scaling이 어떻게 함께 동작하는지 설명해 보세요. 트래픽이 갑자기 증가했을 때 어떤 일이 순서대로 발생하는지 포함해 주세요.
💡 사용자 요청 → ALB → Target Group → EC2, 그리고 CloudWatch → ASG의 두 가지 흐름을 연결해서 설명해 보세요.
트러블슈팅
Target Group의 인스턴스가 unhealthy인 경우:
- EC2 인스턴스에서 웹 서버(httpd)가 실행 중인지 확인:
systemctl status httpd - 보안 그룹에서 ALB → EC2로의 HTTP(80) 트래픽이 허용되어 있는지 확인
- 헬스 체크 경로(
/)에 대해 HTTP 200을 반환하는지 확인:curl localhost - User Data 스크립트가 정상 실행되었는지 확인:
/var/log/cloud-init-output.log
Scale Out이 동작하지 않는 경우:
- CloudWatch → 경보에서 Auto Scaling 관련 경보 상태 확인
- 인스턴스 한 대만 stress를 걸면 평균 CPU가 충분히 올라가지 않을 수 있음 → 모든 인스턴스에 부하 필요
- ASG의 최대 용량이 현재 인스턴스 수와 같으면 Scale Out 불가 → 최대 용량 확인
- 쿨다운 기간 중에는 추가 스케일링이 발생하지 않음 → 잠시 대기
ALB DNS로 접속 시 502 Bad Gateway 에러:
- Target Group에 healthy 인스턴스가 하나도 없는 상태입니다
- 인스턴스가 아직 초기화 중일 수 있으므로 2~3분 대기
- EC2에서 웹 서버 포트와 Target Group 포트가 일치하는지 확인 (둘 다 80)
완성 후 테스트 가이드
전체 구성이 완료되었다면, 다음 시나리오를 테스트하여 정상 동작을 확인하세요.
- 1로드밸런싱 테스트: 브라우저에서 ALB DNS를 10회 새로고침 → Instance ID가 번갈아 표시되는지 확인
- 2헬스 체크 테스트: EC2 하나에 접속하여 sudo systemctl stop httpd로 웹 서버 중지 → 1~2분 후 Target Group에서 unhealthy로 변경 확인 → 브라우저에서 접속 시 다른 인스턴스만 응답하는지 확인 → 다시 sudo systemctl start httpd로 복구
- 3Scale Out 테스트: 모든 인스턴스에서 stress --cpu 4 --timeout 300 실행 → CloudWatch 경보 확인 → 2~3분 후 새 인스턴스가 추가되는지 확인
- 4Scale In 테스트: stress 종료 후 5~15분 대기 → 추가된 인스턴스가 자동 종료되는지 확인
- 5장애 복구 테스트: EC2 인스턴스 하나를 강제 종료 → ASG가 자동으로 새 인스턴스를 생성하는지 확인
확장 아이디어
- HTTPS 적용: ACM에서 SSL 인증서를 발급하고 ALB에 HTTPS 리스너(443)를 추가합니다. HTTP → HTTPS 리다이렉트도 설정해 보세요.
- 경로 기반 라우팅:
/api/*는 백엔드 Target Group으로,/는 프론트엔드 Target Group으로 라우팅하는 규칙을 만들어 보세요. - 스케줄 기반 스케일링: 매일 오전 9시에 인스턴스를 4개로 늘리고, 밤 10시에 2개로 줄이는 예약 스케일링을 설정해 보세요.
- Blue/Green 배포: 새 버전의 Launch Template을 만들고, 인스턴스 새로 고침(Instance Refresh)으로 무중단 배포를 해 보세요.
- ALB Access Log: ALB 접속 로그를 S3에 저장하고, Athena로 분석해 보세요.
학습 정리
핵심 치트시트
이 프로젝트에서는 ALB로 트래픽을 분산하고, Auto Scaling으로 인스턴스 수를 자동 관리하는 고가용성 인프라를 구축했습니다. 핵심은 Launch Template + ALB + Target Group + ASG의 조합입니다.
리소스 정리
실습 완료 후 반드시 아래 순서대로 리소스를 정리하여 불필요한 과금을 방지하세요. ALB와 EC2는 시간당 비용이 발생하므로 반드시 삭제해야 합니다.
- Auto Scaling Group 삭제 (인스턴스 자동 종료됨 — 완전 종료까지 2~3분 소요)
- 시작 템플릿 삭제
- Target Group 삭제
- Application Load Balancer 삭제
- 보안 그룹 삭제 (커스텀)
- (VPC는 다른 실습에서 사용 시 유지)