왜 이걸 만들까? — AI 챗봇이 필요한 순간
"고객 문의 응답 시간을 줄이고 싶어요." "자사 매뉴얼에 기반한 정확한 답변을 자동으로 제공하고 싶어요." 이런 요구는 이제 거의 모든 기업에서 들립니다.
여러분이 한 SaaS 스타트업의 개발자라고 상상해 보세요. 고객 지원팀은 매일 같은 질문에 반복 답변하느라 지쳐 있고, 신규 기능 출시 때마다 FAQ 문서를 업데이트하는 것도 부담입니다. "우리 제품 문서를 AI가 읽고 고객에게 정확히 답변해 주면 좋겠는데..."라는 생각이 들죠.
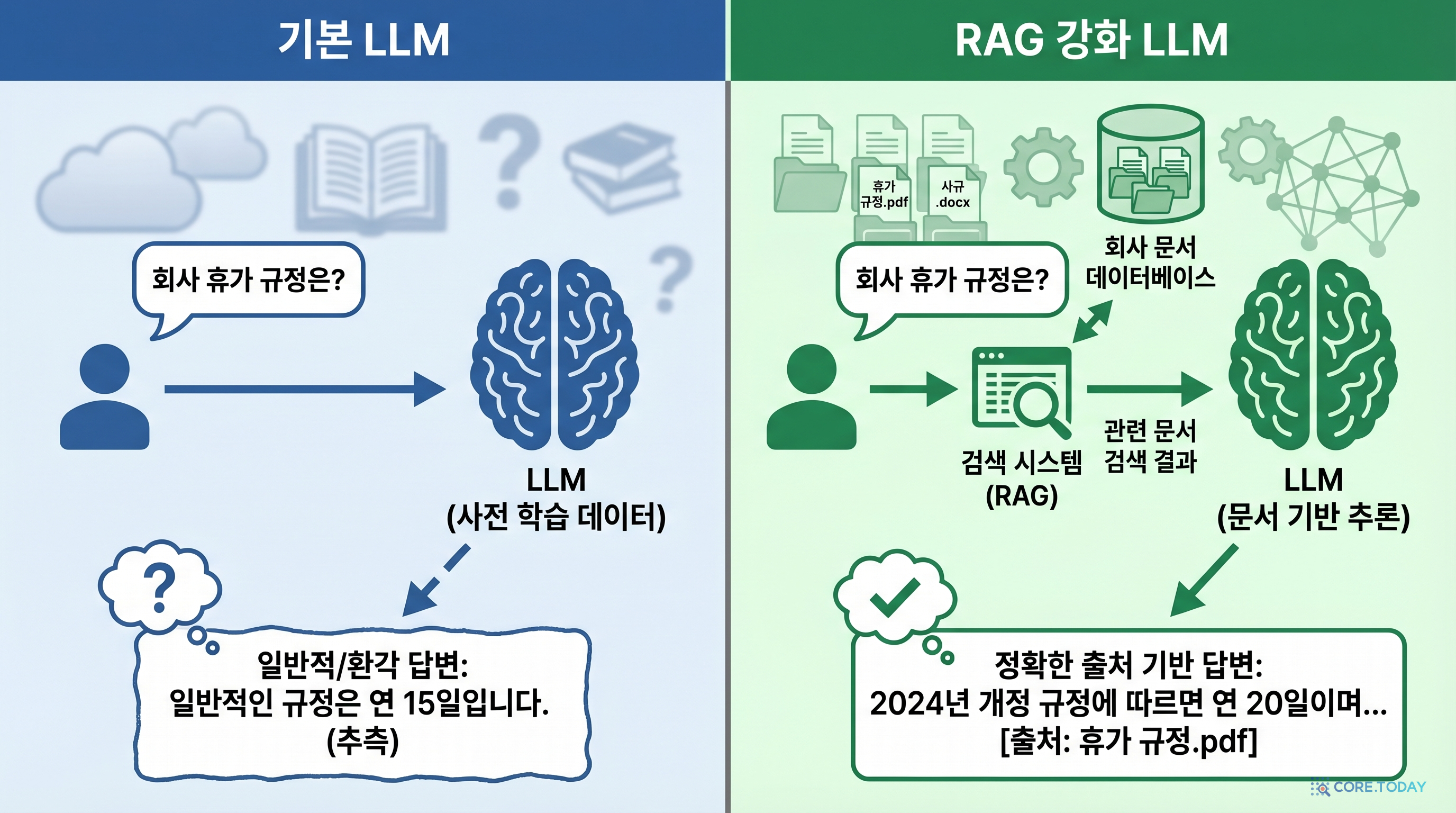
하지만 GPT나 Claude 같은 범용 모델에 질문하면, 우리 회사 제품에 특화된 정보를 알지 못합니다. 모델을 직접 파인튜닝하자니 비용과 시간이 만만치 않습니다.
바로 여기서 RAG(Retrieval-Augmented Generation) 기법이 빛을 발합니다.
RAG는 사용자가 질문하면:
- 검색(Retrieval): 우리 회사 문서 중에서 관련 내용을 찾고
- 생성(Generation): 그 내용을 바탕으로 AI가 자연스러운 답변을 만들어 줍니다
모델을 재학습시키지 않아도, 우리 문서만 업로드하면 우리 회사 전용 AI 상담사가 완성됩니다.
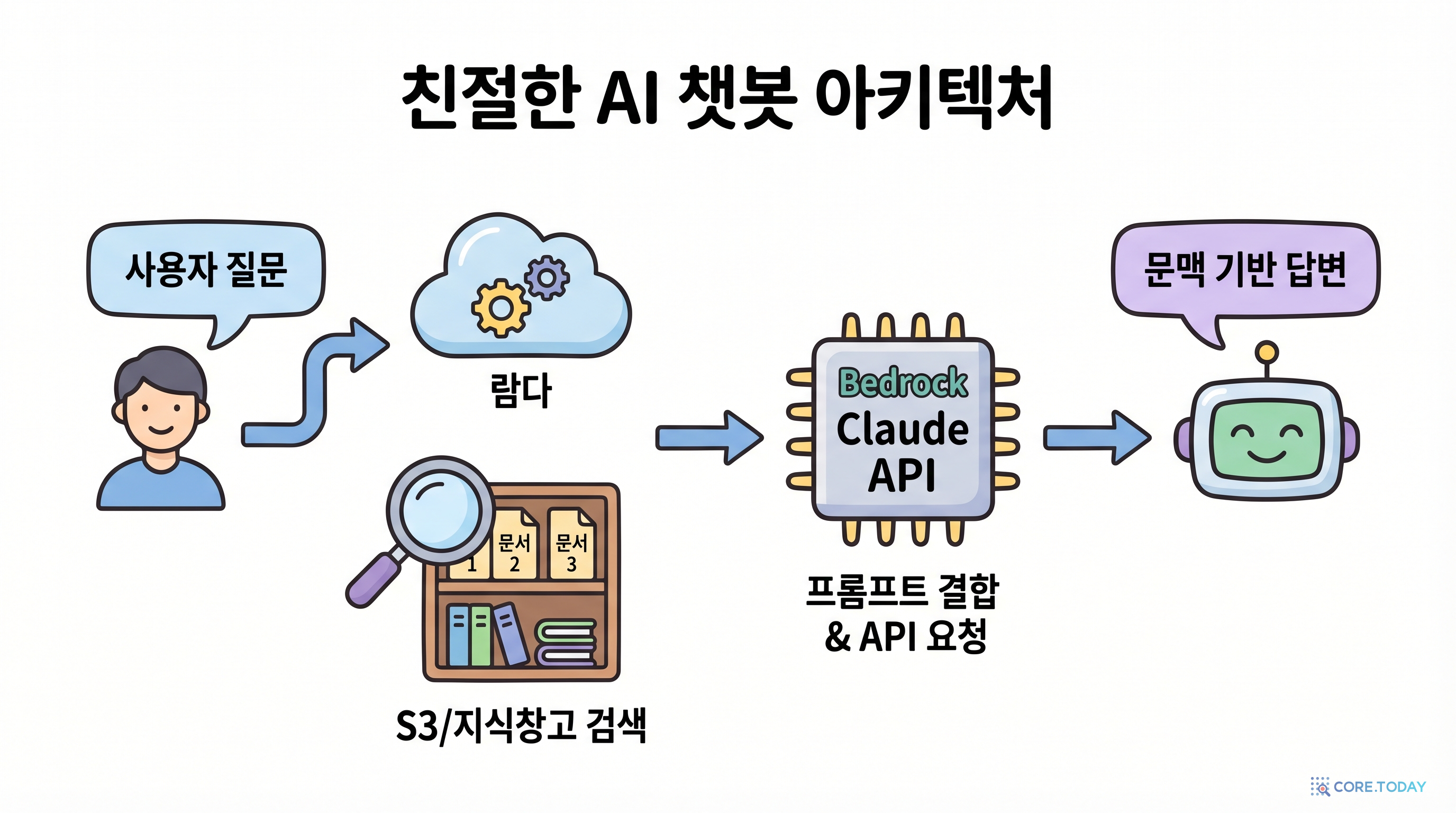
이 실습에서는 Amazon Bedrock의 Foundation Model과 Knowledge Base 기능을 활용하여, S3에 업로드한 문서를 기반으로 질문에 답변하는 RAG 챗봇을 직접 만들어 봅니다.
완성하면 이런 흐름이 동작합니다:
- 사용자가 API로 질문을 보냄 (예: "환불 절차가 어떻게 되나요?")
- Lambda가 Bedrock을 호출하여, Knowledge Base에서 관련 문서를 찾아 답변 생성
- 출처(Source)까지 포함된 정확한 답변이 JSON으로 반환
- 문서에 없는 내용을 질문하면 "해당 정보를 찾을 수 없습니다"라고 솔직히 답변
이 프로젝트를 통해 배우게 되는 것:
- Amazon Bedrock API 사용법: Foundation Model을 API로 호출하는 방법
- RAG 아키텍처: 외부 문서 기반 AI 답변 생성 원리
- 프롬프트 엔지니어링: Temperature, Top-P, System Prompt 활용법
- 서버리스 API 구축: Lambda + API Gateway로 챗봇 엔드포인트 배포
실습을 시작하기 전에 AWS 콘솔에 로그인되어 있는지 확인하세요. 리전은 us-east-1 (버지니아 북부) 을 사용합니다. Bedrock 모델 가용성이 가장 높은 리전입니다.
아키텍처 개요
데이터 흐름
비용 예측
비용 계산기
입력 1K 토큰 $0.008
입력 1K 토큰 $0.008
시간당 과금
OCU/시간 (최소 2 OCU)
100만 요청당 $0.20 + 실행시간
* 실제 비용은 AWS 요금 정책에 따라 달라질 수 있습니다.
Step 1: Bedrock 모델 액세스 활성화
이 단계에서는 실습에 사용할 AI 모델의 접근 권한을 활성화합니다. Bedrock은 보안을 위해 모델별로 명시적 승인이 필요합니다. 한 번 활성화하면 해당 리전에서 계속 사용할 수 있습니다.
- AWS 콘솔 → Amazon Bedrock 서비스 이동
- 좌측 메뉴 → 모델 액세스 클릭
- 모델 액세스 관리 버튼 클릭
- Anthropic - Claude 3 Haiku 와 Amazon - Titan Embeddings 체크
- 변경 사항 저장 클릭 → 승인까지 수 분 대기
- 상태가 접근 허용됨으로 바뀌었는지 반드시 확인
# 모델 액세스 상태 확인
aws bedrock list-foundation-models \
--region us-east-1 \
--query "modelSummaries[?providerName=='Anthropic'].modelId"모델 액세스 승인은 보통 수 분 내에 완료되지만, 일부 모델은 최대 24시간이 걸릴 수 있습니다. Haiku 모델은 비용 대비 성능이 우수하여 실습에 적합합니다.
흔한 실수: 모델 액세스를 활성화하지 않고 API를 호출하면 AccessDeniedException이 발생합니다.
또한 리전마다 별도로 활성화해야 하므로, us-east-1에서 활성화한 것이 서울 리전에는 적용되지 않습니다.
반드시 실습 리전(us-east-1)에서 활성화 상태를 확인하세요.
Step 2: Knowledge Base 생성 (S3 문서 업로드)
Knowledge Base는 RAG의 핵심입니다. 문서를 업로드하면 Bedrock이 자동으로 텍스트를 청크(chunk) 단위로 분할하고, 각 청크를 벡터 임베딩으로 변환하여 OpenSearch Serverless에 저장합니다. 사용자가 질문하면 질문도 임베딩으로 변환하여, 가장 유사한 문서 청크를 찾아 답변에 활용합니다.
- 1S3 콘솔 → 버킷 생성 → 이름: chatbot-kb-docs-{계정ID} (계정 ID는 콘솔 우측 상단에서 확인)
- 2실습용 FAQ 문서 (PDF/TXT) 3~5개를 버킷에 업로드 — 예: 회사 소개, 제품 FAQ, 사용 가이드 등
- 3업로드한 파일이 정상적으로 버킷에 보이는지 확인 (파일명에 한글/특수문자 주의)
- 4Bedrock 콘솔 → 좌측 메뉴 → Knowledge Base → 생성 클릭
- 5이름 입력 후, 데이터 소스: S3 버킷 선택 → 방금 만든 버킷 경로 지정
- 6임베딩 모델: Titan Embeddings V2 선택 (한국어 지원, 비용 저렴)
- 7벡터 데이터베이스: 빠른 생성 (OpenSearch Serverless) 선택 → 자동으로 컬렉션 생성됨
- 8Knowledge Base 생성 클릭 → 완료까지 약 2~3분 대기
- 9생성 완료 후 동기화 버튼 클릭하여 S3 문서를 인덱싱
- 10동기화 상태가 완료로 바뀌면 Knowledge Base ID를 메모
OpenSearch Serverless 비용 주의: Knowledge Base 생성 시 OpenSearch Serverless 컬렉션이 자동 생성되며, 최소 2 OCU(약 시간당 $0.48)가 과금됩니다. 실습 완료 후 반드시 삭제하세요. 비용을 최소화하려면 Knowledge Base 테스트를 한꺼번에 진행하고 빠르게 정리하는 것을 권장합니다.
Step 3: Lambda 함수 작성 (Bedrock API 호출)
이 Lambda 함수가 챗봇의 두뇌 역할을 합니다. 사용자 메시지를 받아 Bedrock Claude 모델을 호출하고, 결과를 정리하여 반환합니다. 시스템 프롬프트로 모델의 역할과 언어를 제어하는 것이 핵심입니다.
- Lambda 콘솔 → 함수 생성 → 이름:
chatbot-bedrock-handler - 런타임: Python 3.12, 아키텍처: arm64 (비용 20% 절감)
- 실행 역할에 AmazonBedrockFullAccess 정책 추가 (실습용; 프로덕션에서는 최소 권한 적용)
- 일반 구성 → 제한 시간: 60초로 변경 (Bedrock 응답 대기 필요)
- 일반 구성 → 메모리: 256MB (boto3 + JSON 처리에 충분)
- 아래 코드를 함수 코드에 붙여넣기 → Deploy 클릭
# Lambda 함수 생성
aws lambda create-function \
--function-name chatbot-bedrock-handler \
--runtime python3.12 \
--handler lambda_function.lambda_handler \
--role arn:aws:iam::YOUR_ACCOUNT:role/lambda-bedrock-role \
--timeout 60 --memory-size 256 \
--zip-file fileb://function.zip아래는 Bedrock Claude 모델을 호출하는 Lambda 함수의 전체 코드입니다. Lambda 콘솔의 코드 편집기에 붙여넣으세요.
# chatbot-bedrock-handler Lambda — Bedrock Claude 호출 (Python 3.12 런타임)
import json
import boto3
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
def lambda_handler(event, context):
body = json.loads(event['body'])
user_message = body['message']
# Claude 3 Sonnet 모델 호출
response = bedrock.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
contentType='application/json',
body=json.dumps({
'anthropic_version': 'bedrock-2023-05-31',
'max_tokens': 1024,
'system': '당신은 AWS 클라우드 전문가입니다. 한국어로 답변하세요.',
'messages': [
{'role': 'user', 'content': user_message}
]
})
)
result = json.loads(response['body'].read())
assistant_message = result['content'][0]['text']
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
},
'body': json.dumps({
'message': assistant_message,
'usage': {
'input_tokens': result['usage']['input_tokens'],
'output_tokens': result['usage']['output_tokens']
}
}, ensure_ascii=False)
}anthropic_version은 반드시 bedrock-2023-05-31로 지정해야 합니다.
system 파라미터로 모델의 역할과 언어를 설정하고, max_tokens로 응답 길이를
제한합니다. ensure_ascii=False는 한국어 응답이 이스케이프되지 않도록 합니다.
타임아웃 설정 주의: Lambda 기본 타임아웃은 3초입니다. Bedrock 모델 호출은 응답까지 5~30초가 걸릴 수 있으므로,
반드시 60초 이상으로 설정하세요. 타임아웃이 짧으면 Task timed out 에러가 발생합니다.
Step 4: API Gateway 엔드포인트 설정
API Gateway는 외부에서 챗봇에 접근할 수 있는 HTTPS 엔드포인트를 제공합니다. 이 단계에서 REST API를 생성하고, /chat 경로에 POST 요청을 받아 Lambda로 전달하도록 구성합니다.
- 1API Gateway 콘솔 → REST API → 생성 (HTTP API가 아닌 REST API를 선택)
- 2API 이름: chatbot-api, 설명: "Bedrock RAG 챗봇 API"
- 3리소스 /chat 생성: 작업 → 리소스 만들기 → 리소스 이름 chat
- 4/chat 리소스에 POST 메서드 추가 → 통합 유형: Lambda 함수 → chatbot-bedrock-handler 선택
- 5CORS 활성화 설정: /chat 리소스 선택 → 작업 → CORS 활성화 → 확인
- 6API 배포: 작업 → API 배포 → 새 스테이지 생성 → 이름: dev
- 7배포 완료 후 표시되는 Invoke URL을 복사하여 메모 (예: https://abc123.execute-api.us-east-1.amazonaws.com/dev)
Step 5: 프롬프트 엔지니어링 실습
프롬프트 엔지니어링은 AI 모델에게 어떻게 질문하느냐에 따라 답변 품질이 크게 달라지는 기법입니다. 같은 모델이라도 프롬프트를 잘 설계하면 훨씬 정확하고 유용한 답변을 얻을 수 있습니다.
- 1Bedrock 콘솔 → 플레이그라운드 → 텍스트 탭
- 2시스템 프롬프트에 역할/규칙 정의: "당신은 AWS 클라우드 전문 상담사입니다. 항상 한국어로 답변하세요. 모르는 내용은 모른다고 말하세요."
- 3Temperature를 0.1, 0.5, 1.0으로 바꿔가며 같은 질문에 대한 응답 품질 비교
- 4Top-P 파라미터를 0.5, 0.9로 조정하며 응답의 다양성 차이 관찰
- 5Knowledge Base를 연결하여 RAG 응답과 일반 응답의 정확도 차이 비교
- 6Few-shot 예시를 추가하여 응답 형식(예: 번호 리스트, 표 형식) 제어 실습
Temperature를 0에 가깝게 설정하면 일관된 답변을, 1에 가깝게 설정하면 창의적 답변을 생성합니다. 프로덕션 챗봇에서는 보통 0.1~0.3 범위를 사용합니다.
Step 6: RAG 정확도 테스트
실제 챗봇이 잘 동작하는지 체계적으로 테스트합니다. Knowledge Base에 있는 내용과 없는 내용을 구분하여 질문하고, 응답의 정확성과 지연 시간을 측정합니다.
- 1API Gateway 엔드포인트로 테스트 질문 5개 전송 (curl 또는 Postman 사용)
- 2Knowledge Base 문서에 있는 내용 질문 → 정확한 출처 기반 응답 확인
- 3Knowledge Base에 없는 내용 질문 → "모르겠습니다" 또는 "해당 정보가 문서에 없습니다" 응답 확인
- 4응답의 source attribution(출처 표시) 동작 확인 — 어떤 문서의 몇 번째 청크에서 가져왔는지
- 5응답 지연 시간(Latency) 측정: 첫 요청(콜드 스타트) vs 연속 요청(웜 스타트) 차이 기록
- 6결과를 표로 정리: 질문 | 기대 답변 | 실제 답변 | 정확도 | 지연 시간
본인의 말로 설명해 보세요
친구에게 'RAG(Retrieval-Augmented Generation)가 뭔지, 왜 모델을 재학습시키지 않아도 우리 회사 문서로 정확한 답변을 생성할 수 있는지'를 도서관 사서 비유를 사용하여 설명해 보세요.
핵심 개념 확인
트러블슈팅 가이드
AccessDeniedException 에러가 발생할 때:
- Bedrock 모델 액세스가 활성화되어 있는지 확인 (Step 1)
- Lambda 실행 역할에
AmazonBedrockFullAccess정책이 연결되어 있는지 확인 - 리전이 us-east-1인지 확인 — Lambda 코드의
region_name과 콘솔 리전이 일치해야 합니다
Lambda 타임아웃 (Task timed out) 에러:
- 일반 구성 → 제한 시간이 60초 이상인지 확인
- Bedrock 모델 응답은 5~30초 소요될 수 있으므로 여유 있게 설정
- 메모리가 너무 낮으면(128MB 이하) CPU 성능 저하로 지연이 발생할 수 있음
Knowledge Base 동기화 실패:
- S3 버킷 이름과 Knowledge Base 데이터 소스의 경로가 정확히 일치하는지 확인
- 문서 형식이 지원되는지 확인 (PDF, TXT, HTML, DOCX, CSV, MD 지원)
- IAM 역할에 S3 읽기 권한이 포함되어 있는지 확인
- 파일명에 한글이나 특수문자가 포함되면 오류가 발생할 수 있음 — 영문 파일명 권장
완성 후 테스트 가이드
모든 구성이 완료되었다면, 아래 체크리스트로 전체 시스템을 단계적으로 검증하세요. 테스트는 개별 컴포넌트 → 통합 → 엣지 케이스 순서로 진행합니다:
- API 연결 테스트:
curl -X POST https://{api-id}.execute-api.us-east-1.amazonaws.com/dev/chat -H "Content-Type: application/json" -d '{"message": "안녕하세요"}'→ 200 응답 확인 - RAG 정확도 테스트: Knowledge Base 문서에 있는 내용으로 질문 → 문서 기반 정확한 답변 확인
- Hallucination 방지 테스트: 문서에 없는 내용으로 질문 → "해당 정보를 찾을 수 없습니다" 류의 답변 확인
- 토큰 사용량 확인: 응답 JSON의
usage필드에서 입력/출력 토큰 수 확인 - 성능 측정: 5회 연속 호출하여 평균 응답 시간 기록 (목표: 5초 이내)
- 에러 핸들링: 빈 메시지, 특수문자, 매우 긴 메시지 전송 시 적절한 에러 메시지 반환 확인
- 비용 확인: Bedrock 콘솔 → 사용량 탭에서 실습 중 소비한 토큰 수와 예상 비용 확인
- CloudWatch 로그 확인: Lambda 함수의 실행 시간, 메모리 사용량, 에러 여부를 로그에서 확인
확장 아이디어
- 대화 히스토리 추가: DynamoDB에 세션별 대화 이력을 저장하고, 이전 대화 맥락을 포함하여 연속 대화 지원
- 스트리밍 응답 구현: Bedrock의
invoke_model_with_response_streamAPI를 사용하여 답변이 실시간으로 글자 단위로 출력되도록 구현 - 다중 Knowledge Base: 부서별(영업, 기술지원, HR) Knowledge Base를 분리하고, 질문 의도에 따라 자동 라우팅
- Guardrails 적용: Bedrock Guardrails로 부적절한 질문 필터링, 민감 정보(PII) 자동 마스킹 구현
- 비용 모니터링 대시보드: CloudWatch 커스텀 메트릭으로 일별 토큰 사용량/비용을 추적하는 대시보드 구축
학습 정리
핵심 치트시트
Amazon Bedrock Knowledge Base와 RAG 패턴으로 자사 문서 기반 AI 챗봇을 구축했습니다. S3에 문서를 업로드하면 자동으로 벡터 임베딩으로 변환되어 검색 가능해지고, Lambda + API Gateway로 서버리스 API를 구성하여 외부에서 접근할 수 있는 챗봇 엔드포인트를 완성했습니다.
핵심 개념
- •RAG (Retrieval-Augmented Generation) — AI 모델이 답변을 생성할 때, 외부 문서에서 관련 정보를 검색하여 프롬프트에 포함시키는 기법. 모델 재학습 없이 최신/도메인 특화 정보를 반영할 수 있고, 환각(hallucination)을 크게 줄입니다.
- •벡터 임베딩 (Vector Embedding) — 텍스트를 수백~수천 차원의 수치 벡터로 변환한 것. 의미가 비슷한 텍스트는 벡터 공간에서 가까운 위치에 배치됩니다. Knowledge Base는 Titan Embeddings 모델로 문서와 질문을 임베딩하여 유사도를 계산합니다.
- •Foundation Model (FM) — 대규모 데이터로 사전 학습된 범용 AI 모델. Bedrock에서는 Claude(Anthropic), Titan(Amazon), Llama(Meta) 등을 API로 제공합니다. 파인튜닝 없이도 프롬프트 엔지니어링만으로 다양한 작업에 활용 가능합니다.
- •프롬프트 엔지니어링 — AI 모델에 최적의 입력(프롬프트)을 설계하는 기법. 시스템 프롬프트(역할 부여), Few-shot(예시 제공), Temperature/Top-P(응답 다양성 조절) 등의 기법이 있습니다.
- •Knowledge Base 동기화 — S3에 업로드된 문서를 청크로 분할하고 벡터 임베딩으로 변환하여 벡터 DB에 저장하는 과정. 문서 추가/수정 시 재동기화하면 검색 결과가 자동으로 업데이트됩니다.
- •OpenSearch Serverless — Knowledge Base의 벡터 임베딩을 저장하고 유사도 검색을 수행하는 완전관리형 벡터 데이터베이스. 자동 스케일링되지만 최소 2 OCU 과금에 주의가 필요합니다.
흔한 실수
- Bedrock 모델 액세스를 활성화하지 않고 API 호출 시도 — AccessDeniedException 발생
- Lambda 타임아웃을 기본값(3초)으로 두어 Bedrock 응답 전에 함수가 종료됨
- anthropic_version을 잘못 지정하거나 누락하여 400 에러 발생
- Knowledge Base 문서에 한글 파일명을 사용하여 동기화 실패
- OpenSearch Serverless 컬렉션을 삭제하지 않아 예상치 못한 과금 발생
- system 프롬프트 없이 호출하여 모델이 영어로 답변하거나 역할을 벗어난 응답 생성
| 일반 Bedrock 호출 (RAG 없음) | RAG 기반 Bedrock 호출 |
|---|---|
| 모델의 학습 데이터에만 의존 | 외부 문서에서 관련 내용 검색 후 답변 |
| 최신 정보 반영 불가 | 문서 업데이트로 즉시 최신 정보 반영 |
| 도메인 특화 정보 부족 | 자사 문서 기반 정확한 답변 |
| 환각(Hallucination) 발생 가능 | 출처 기반 답변으로 환각 최소화 |
| 추가 비용 없음 | 임베딩 + 벡터 DB 비용 추가 |
본인의 말로 설명해 보세요
비개발자인 마케팅 팀장에게 '우리가 만든 RAG 챗봇이 일반 ChatGPT와 어떻게 다른지, 왜 더 정확한 답변을 할 수 있는지'를 1분 안에 설명해 보세요.
리소스 정리
실습 완료 후 반드시 아래 순서대로 리소스를 정리하여 불필요한 과금을 방지하세요. 특히 OpenSearch Serverless 컬렉션은 시간당 $0.48이 과금되므로 가장 먼저 삭제하는 것을 권장합니다.
- Bedrock Knowledge Base 삭제 (연결된 OpenSearch Serverless 컬렉션도 함께 삭제됨)
- API Gateway API 삭제
- Lambda 함수 삭제
- S3 버킷 비우기 및 삭제
- IAM 역할 및 정책 삭제
- CloudWatch 로그 그룹 삭제